Research question(s). State your research question (s) clearly.
How has the price of books changed throughout time based on the rating, genre, and ranking of the book?
Data collection and cleaning
Have an initial draft of your data cleaning appendix. Document every step that takes your raw data file(s) and turns it into the analysis-ready data set that you would submit with your final project. Include text narrative describing your data collection (downloading, scraping, surveys, etc) and any additional data curation/cleaning (merging data frames, filtering, transformations of variables, etc). Include code for data curation/cleaning, but not collection.
# A tibble: 1,291 × 10
id price ranks title no_of…¹ ratings author cover…² year genre
<dbl> <dbl> <dbl> <chr> <dbl> <dbl> <chr> <chr> <dbl> <chr>
1 0 12.5 1 The Lost Symbol 16118 4.4 Dan B… Hardco… 2009 Fict…
2 1 13.4 2 The Shack: Wher… 23392 4.7 Willi… Paperb… 2009 Fict…
3 2 9.93 3 Liberty and Tyr… 5036 4.8 Mark … Hardco… 2009 Non …
4 3 14.3 4 Breaking Dawn (… 16912 4.7 Steph… Hardco… 2009 Fict…
5 4 9.99 5 Going Rogue: An… 1572 4.6 Sarah… Hardco… 2009 Non …
6 5 18.3 6 StrengthsFinder… 7082 4.1 Gallup Hardco… 2009 Non …
7 6 12.7 7 The Help 18068 4.8 Kathr… Hardco… 2009 Fict…
8 7 17.6 8 New Moon (The T… 12329 4.7 Steph… Paperb… 2009 Fict…
9 8 58.9 9 The Twilight Sa… 6100 4.7 Steph… Hardco… 2009 Fict…
10 9 16.0 10 Outliers: The S… 22209 4.7 Malco… Hardco… 2009 Non …
# … with 1,281 more rows, and abbreviated variable names ¹no_of_reviews,
# ²cover_type
Data description
Have an initial draft of your data description section. Your data description should be about your analysis-ready data.
What are the observations (rows) and the attributes (columns)?
Each observation is one book. Our columns will be year, rating, genre, ranking, and price of the book.
Why was this dataset created?
To observe the top-selling books on Amazon from years 2009 - 2021.
Who funded the creation of the dataset?
The collaborators were Abdulhamid Adavize and Chisom Promise.
What processes might have influenced what data was observed and recorded and what was not?
Amazon might promote a higher-rated book for its audience, leading more customers to buy it and rank it potentially higher (polarizing the ranking of the book). In other words, a self-fulfilling prophecy of ranks.
No digital copies in the data. Only paperback and soft cover (physical books), so we can’t gauge whether a certain time pivoted people to buy less physical books in general.
The fact that the only genres are Non-fiction and Fiction may fail to account for a reason some books are ranked higher than others.
One book with 88 reviews has the same ranking as one with 18,656 reviews. Our original research question fails to capture this.
Inflation.
What preprocessing was done, and how did the data come to be in the form that you are using?
Original collaborators scraped the data from Amazon. The dataset has been cleaned and missing values that could be retrieved from the website has been filled. It only contains some missing values like the name of the books that are no more available in the store. Due to this, the prices, ratings, reviews, and paper cover types of thesis books are probably missing too.
If people are involved, were they aware of the data collection and if so, what purpose did they expect the data to be used for?
Authors of the book probably knew that the information would be public, but maybe not as far as it being scraped from Amazon.
Data limitations
Identify any potential problems with your dataset.
As mentioned above, the dataset does not account for digital copies of the book being sold (Kindle, E-books, etc.), so if at a certain time, more were being sold online, it isn’t accounted for.
This is limited for extrapolation globally because not many countries rely on Amazon to buy books. This is also limited for extrapolation within the U.S. because it only accounts for books and readers on Amazon. Therefore, the findings are not applicable to the entire realm of book preference.
There are also multiple duplicate rows. For example, the book Where the Crawdads Sing is in our dataset five times because it made the top 100 books across four years, but it also counts it twice in 2019 because it is listed as two different books for paperback vs. hardcover. We must account for this in our analysis.
Exploratory data analysis
Perform an (initial) exploratory data analysis.
# take top 5 book titles with the highest number of reviews and use them for rankingbooks |>group_by(title) |>summarise(reviews =mean(no_of_reviews)) |>arrange(desc(reviews)) |>slice_head(n =5)
# A tibble: 5 × 2
title reviews
<chr> <dbl>
1 Where the Crawdads Sing 344811
2 The Midnight Library: A Novel 199570
3 It Ends with Us: A Novel (1) 169014
4 Verity 163818
5 The Silent Patient 135163
# where the crawdads sing is in the dataset multiple times because of the multiple editionsbooks |>filter(title =="Where the Crawdads Sing") |>relocate(id, year)
# A tibble: 5 × 10
id year price ranks title no_of…¹ ratings author cover…² genre
<dbl> <dbl> <dbl> <dbl> <chr> <dbl> <dbl> <chr> <chr> <chr>
1 960 2018 12.4 69 Where the Crawda… 344811 4.8 Delia… Hardco… Fict…
2 991 2019 12.4 1 Where the Crawda… 344811 4.8 Delia… Hardco… Fict…
3 1053 2019 14.0 63 Where the Crawda… 344811 4.8 Delia… Paperb… Fict…
4 1093 2020 12.4 3 Where the Crawda… 344811 4.8 Delia… Hardco… Fict…
5 1242 2021 9.98 52 Where the Crawda… 344811 4.8 Delia… Paperb… Fict…
# … with abbreviated variable names ¹no_of_reviews, ²cover_type
# count # of rank below and above 50books |>mutate(rankclass =if_else(ranks <50, "low", "high")) |>group_by(rankclass) |>summarize(count =n(),mean_rank =mean(ranks)) |>drop_na() |>ungroup()
# A tibble: 2 × 3
rankclass count mean_rank
<chr> <int> <dbl>
1 high 652 74.9
2 low 635 24.9
# A tibble: 2 × 8
genre count year_start year_end mean_ranking mean_price mean_r…¹ mean_…²
<chr> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Fiction 561 2009 2021 NA NA NA NA
2 Non Fiction 723 2009 2021 50.6 14.4 4.63 20276.
# … with abbreviated variable names ¹mean_rating, ²mean_reviews
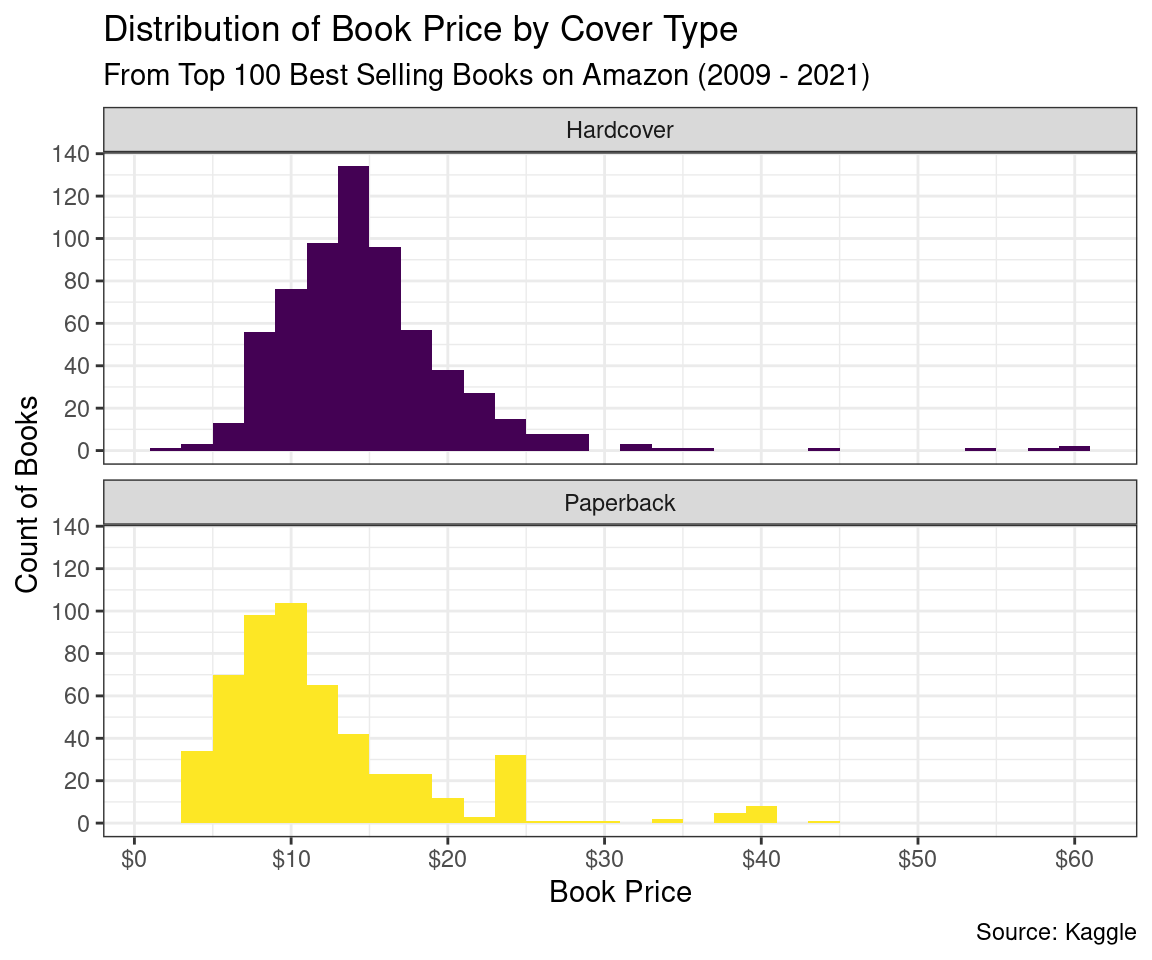
# count paperback vs. hardcover and have prices be another variable books |>filter(cover_type %in%c("Paperback", "Hardcover"), price <60) |>select(id, cover_type, price) |>ggplot(mapping =aes(x = price, fill = cover_type)) +geom_histogram(binwidth =2, show.legend =FALSE) +facet_wrap(facets =vars(cover_type), ncol =1) +labs(title ="Distribution of Book Price by Cover Type",subtitle ="From Top 100 Best Selling Books on Amazon (2009 - 2021)",caption ="Source: Kaggle",x ="Book Price",y ="Count of Books" ) +scale_x_continuous(breaks =seq(0, 60, 10),labels =label_dollar() ) +scale_y_continuous(breaks =seq(0, 140, 20)) +scale_fill_viridis_d(option ="D") +theme_bw()
# look into books that appear across many different yearsbooks[duplicated(books$title),] |>group_by(title) |>summarize(count =n(),year_start =min(year),year_end =max(year),mean_ranking =mean(ranks),mean_price =mean(price),mean_rating =mean(ratings),mean_reviews =mean(no_of_reviews)) |>arrange(desc(count)) |>ungroup()
# A tibble: 236 × 8
title count year_…¹ year_…² mean_…³ mean_…⁴ mean_…⁵ mean_…⁶
<chr> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Publication Manual of … 10 2010 2019 29.4 24.3 4.5 12674
2 StrengthsFinder 2.0 10 2010 2019 19.9 18.3 4.1 7082
3 The 7 Habits of Highly… 9 2010 2018 45.7 18.9 4.66 5849.
4 The Four Agreements: A… 9 2013 2021 25.8 7.74 4.7 86676
5 How to Win Friends & I… 8 2013 2021 43.1 10.5 4.7 79094
6 Love You Forever 8 2014 2021 64.1 4.98 4.9 53161
7 The Great Gatsby: The … 8 2012 2019 53.1 6.79 4.5 18656
8 The Official SAT Study… 8 2010 2018 32.6 34.0 4.43 1731.
9 The Very Hungry Caterp… 8 2014 2021 25.9 4.93 4.9 54008
10 What to Expect When Yo… 8 2012 2021 63.8 15.4 4.8 29389
# … with 226 more rows, and abbreviated variable names ¹year_start, ²year_end,
# ³mean_ranking, ⁴mean_price, ⁵mean_rating, ⁶mean_reviews
# look into most consistently highly-ranked books across multiple yearsbooks |>filter(ranks >=50) |>group_by(title) |>summarize(count =n(),year_start =min(year),year_end =max(year),mean_ranking =mean(ranks),mean_price =mean(price),mean_rating =mean(ratings),mean_reviews =mean(no_of_reviews)) |>arrange(desc(count)) |>ungroup() |>relocate(title, count, mean_ranking)
# A tibble: 472 × 8
title count mean_…¹ year_…² year_…³ mean_…⁴ mean_…⁵ mean_…⁶
<chr> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 What to Expect When Yo… 8 63.8 2012 2021 15.4 4.8 29389
2 Love You Forever 7 71.1 2013 2021 4.98 4.9 53161
3 The Care and Keeping o… 7 75.4 2013 2019 9.48 4.8 24551.
4 The Gifts of Imperfect… 7 65.4 2013 2019 6.92 4.7 29674
5 Dragons Love Tacos 6 84.8 2015 2021 8.95 4.8 15753
6 The Alchemist, 25th An… 6 64.8 2015 2020 13.3 4.7 94750
7 The Great Gatsby: The … 6 66 2011 2019 6.79 4.5 18656
8 Fahrenheit 451 5 67.2 2014 2019 8.29 4.6 34955
9 The Outsiders 5 86.4 2014 2021 9.49 4.8 30584
10 Chicka Chicka Boom Boo… 4 73.2 2014 2021 4.59 4.9 33644
# … with 462 more rows, and abbreviated variable names ¹mean_ranking,
# ²year_start, ³year_end, ⁴mean_price, ⁵mean_rating, ⁶mean_reviews
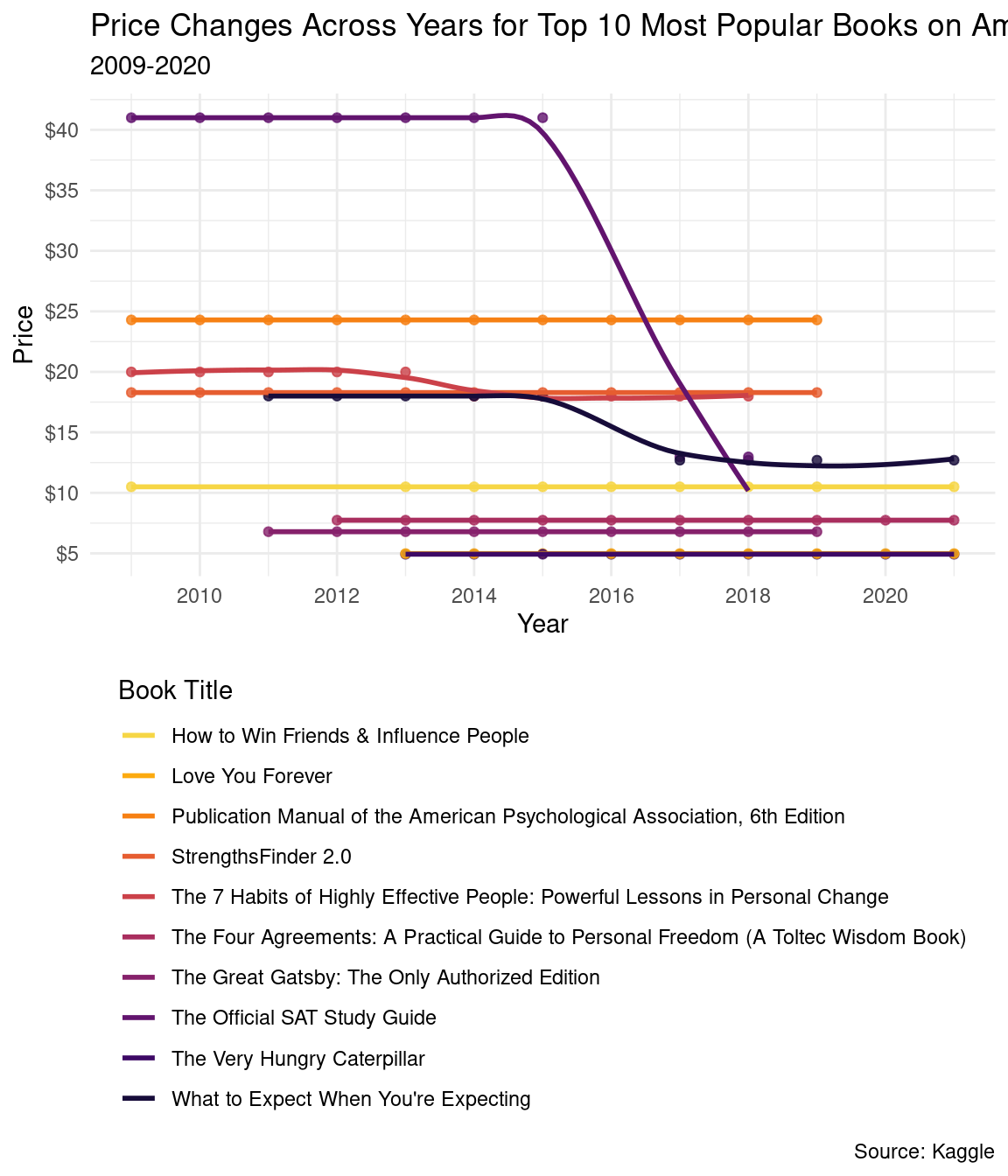
# for top 10 most popular books (based on the number of years it appears in), look into how price over the year might be impacted by inflationpopular_books <- books[duplicated(books$title),] |>group_by(title) |>summarize(count =n()) |>arrange(desc(count)) |>slice_head(n =10) |>distinct(title) |>ungroup()books |>filter(title %in% popular_books$title) |>ggplot(mapping =aes(x = year, y = price, color = title)) +geom_point(show.legend =FALSE, alpha =0.8) +geom_smooth(show.legend =TRUE, se =FALSE) +labs(title ="Price Changes Across Years for Top 10 Most Popular Books on Amazon",subtitle ="2009-2020",x ="Year",y ="Price",color ="Book Title",caption ="Source: Kaggle", ) +scale_x_continuous(breaks =seq(2008, 2020, 2)) +scale_y_continuous(breaks =seq(0, 40, 5),labels =label_dollar() ) +scale_color_viridis_d(option ="B", begin =0.9, end =0.1) +theme_minimal() +theme(legend.position ="bottom",legend.direction ="vertical")
Questions for reviewers
List specific questions for your peer reviewers and project mentor to answer in giving you feedback on this phase.
Is there any other situations you would recommend we explore in our initial analysis? Or, any areas you think would be particularly interesting to look into?