Introduce the topic and motivation
The context of our work is purchase of books on Amazon from 2009 to 2021. We analyze how factors like genre , cover type , rating , and year affect the prices of books over the course of those years.
Research Question: What factors affect book price from the top 100 best-selling books on Amazon from 2009-2021?
Introduce the data
Data comes from Kaggle dataset called ‘TOP 100 BEST SELLING BOOKS ON AMAZON 2009-2021.’ It was scrapped from the Amazon website. The dataset has already been cleaned and missing values that could be retrieved from the website have been filled.
Each observation is 1 book. We further cleaned data from original 10 columns to 5 so that the variables we are interested in are: quantitative (year, rating, price) & categorical (genre, cover type). In considering our variables as predictors, we ensured prevention of model over-fitting, which would hinder our interpretation of the dynamics between each predictors and the price.
Highlights from EDA
── Attaching packages ─────────────────────────────────────── tidyverse 1.3.2 ──
✔ ggplot2 3.4.2 ✔ purrr 1.0.0
✔ tibble 3.2.1 ✔ dplyr 1.1.2
✔ tidyr 1.2.1 ✔ stringr 1.5.0
✔ readr 2.1.3 ✔ forcats 0.5.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
── Attaching packages ────────────────────────────────────── tidymodels 1.0.0 ──
✔ broom 1.0.2 ✔ rsample 1.1.1
✔ dials 1.1.0 ✔ tune 1.1.1
✔ infer 1.0.4 ✔ workflows 1.1.2
✔ modeldata 1.0.1 ✔ workflowsets 1.0.0
✔ parsnip 1.0.3 ✔ yardstick 1.1.0
✔ recipes 1.0.6
── Conflicts ───────────────────────────────────────── tidymodels_conflicts() ──
✖ scales::discard() masks purrr::discard()
✖ dplyr::filter() masks stats::filter()
✖ recipes::fixed() masks stringr::fixed()
✖ dplyr::lag() masks stats::lag()
✖ yardstick::spec() masks readr::spec()
✖ recipes::step() masks stats::step()
• Learn how to get started at https://www.tidymodels.org/start/
New names:
Warning: Removed 7 rows containing missing values (`geom_point()`).
Inference/modeling/other analysis #1
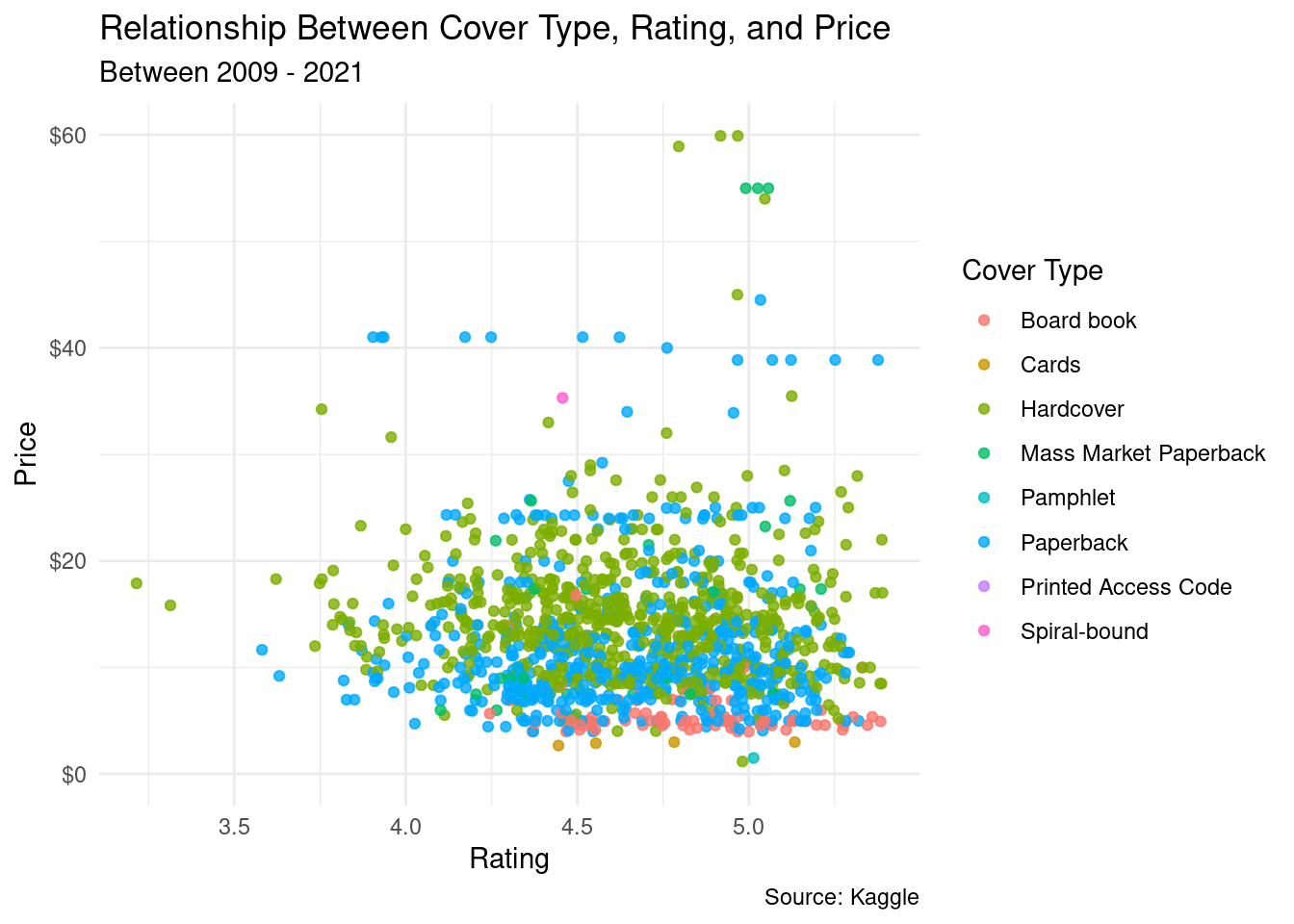
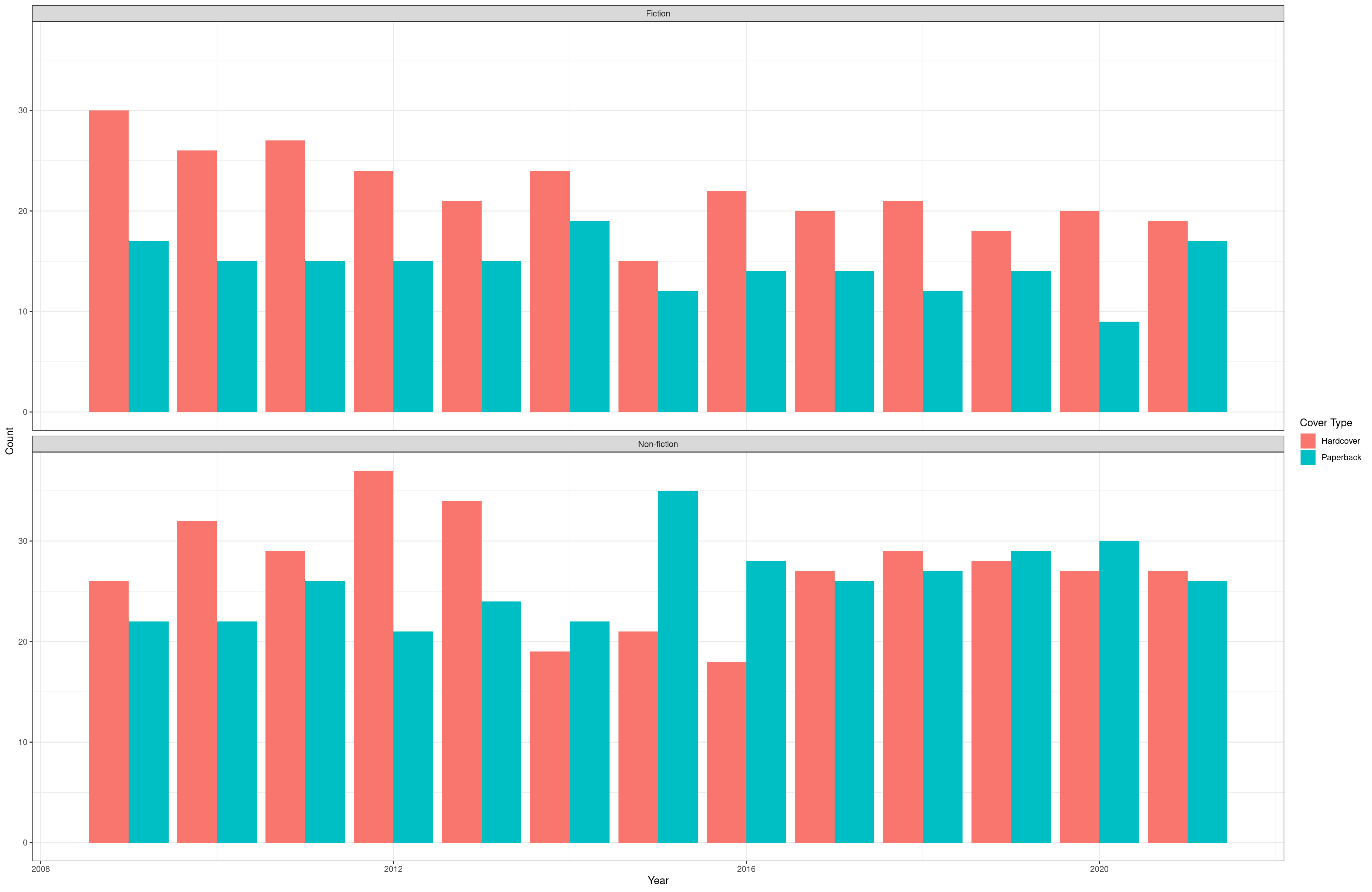
Is the true proportion of prices of books in one cover type different than those of another cover type? We found the p-value = 0.000
Inference/modeling/other analysis #2
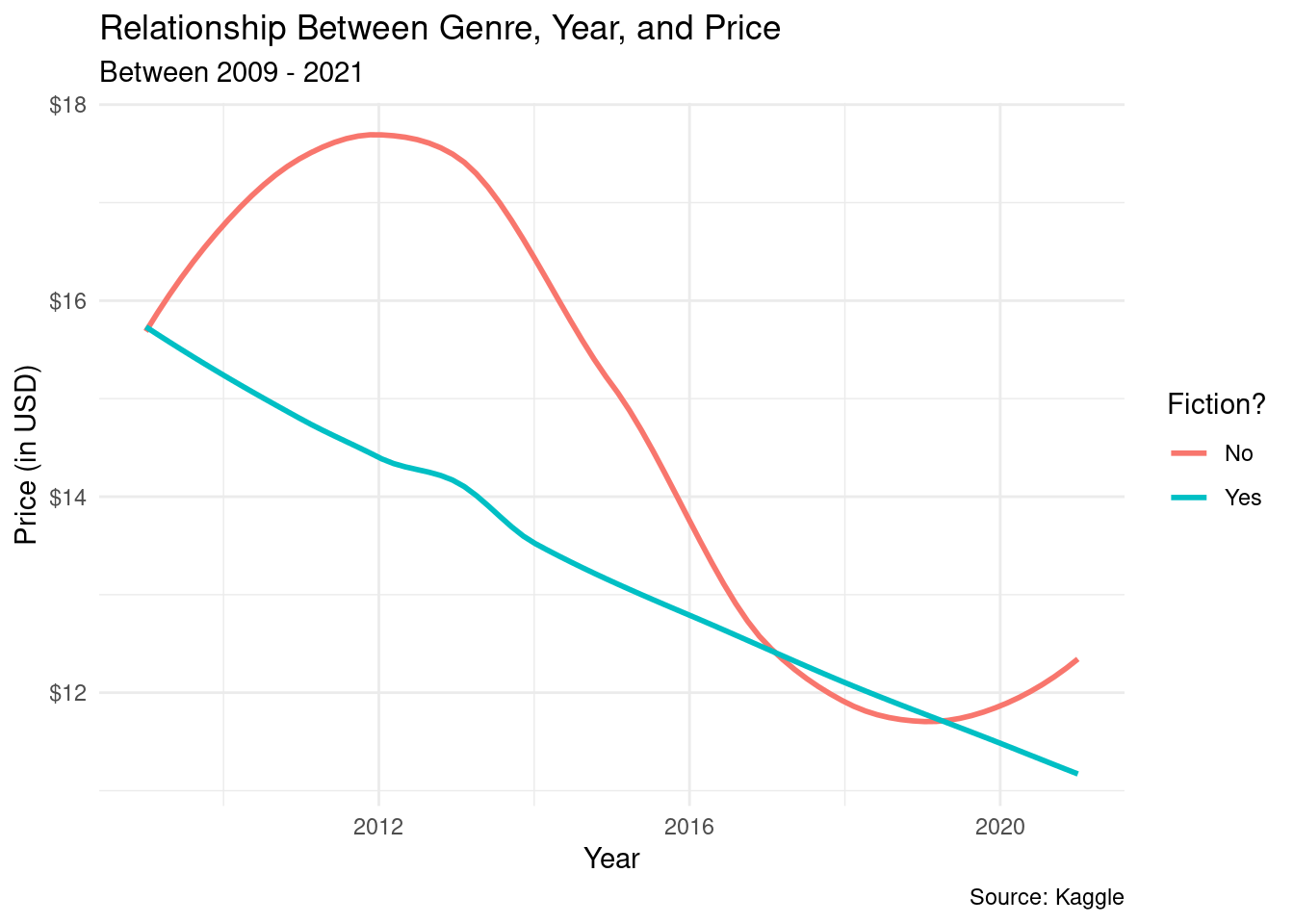
Is the true proportion of prices of books in one genre different than those of another genre? We found the p-value = 0.006.
`geom_smooth()` using method = 'loess' and formula = 'y ~ x'
Conclusions + Future Work
In terms of what factors affect price of a book, one finding so far is that cover type and genre of a book on Amazon may havean impact on price. Based on the p-values we found from our logistic regression model, we found the p-values of the variables cover_type and genre (whether a book was fiction or non-fiction) to be statistically significant to reject the null hypothesis.
The table below provides a summary of the calculated values and their suggestions with regards to the null hypothesis:
| cover_type |
0 |
- supports rejection of the null hypothesis since p < significance level of 0.05
- statistically significant and there is convincing evidence that allows us to reject the null hypothesis. |
| genre |
0.006 |
- supports rejection of the null hypothesis since p < significance level of 0.05
- statistically significant and there is convincing evidence that allows us to reject the null hypothesis. |
In the future, we would hope to explore if additional genres other than just non-fiction vs fiction have an impact on price and we’d like to enlarge our data set to include digital books and different populations of book sales to be able to better generalize the Top 100 Best Selling Books, not just be predominately restricted to paperback and hardback sales on Amazon. However, both of these tasks require collecting a new data set.