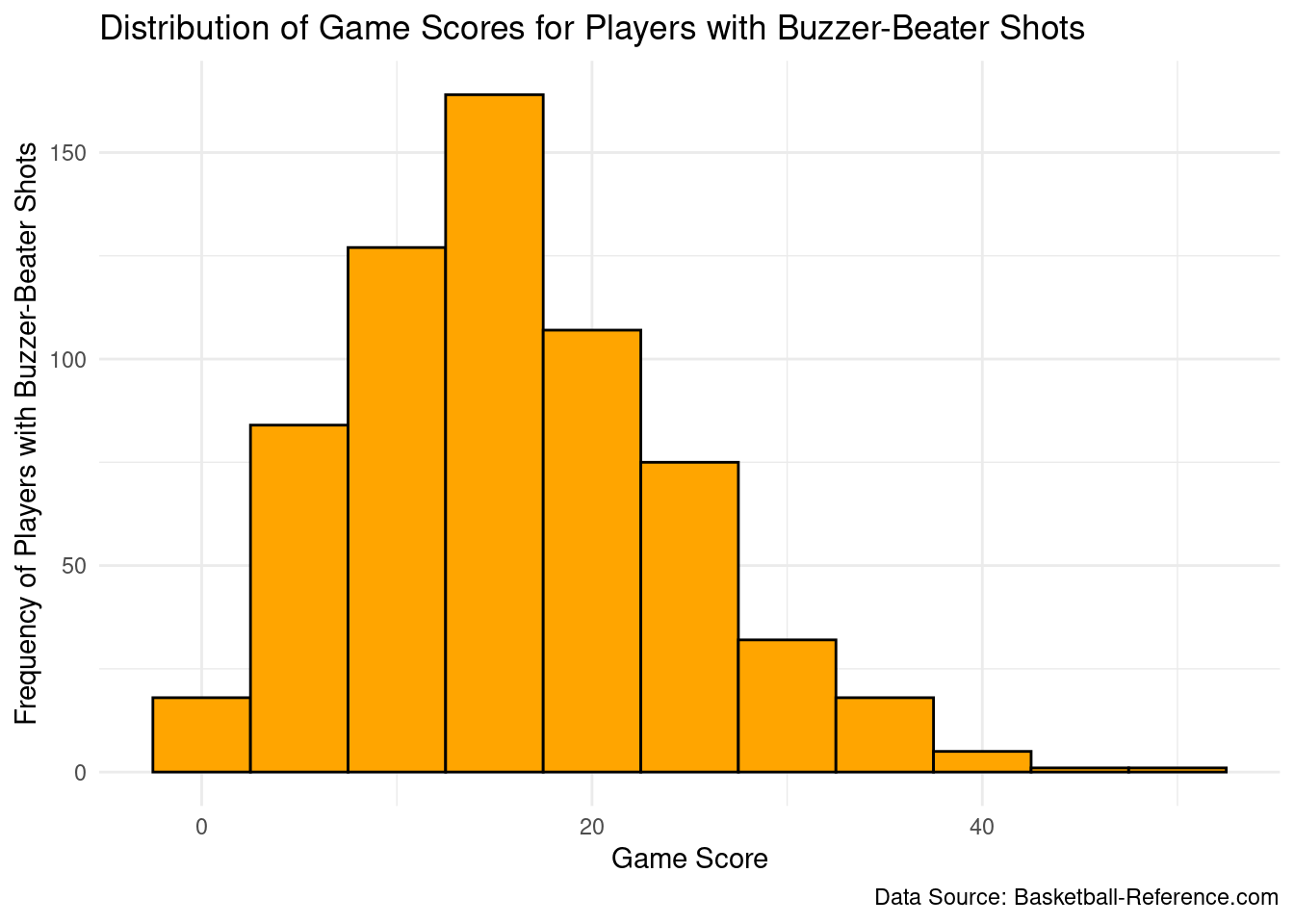
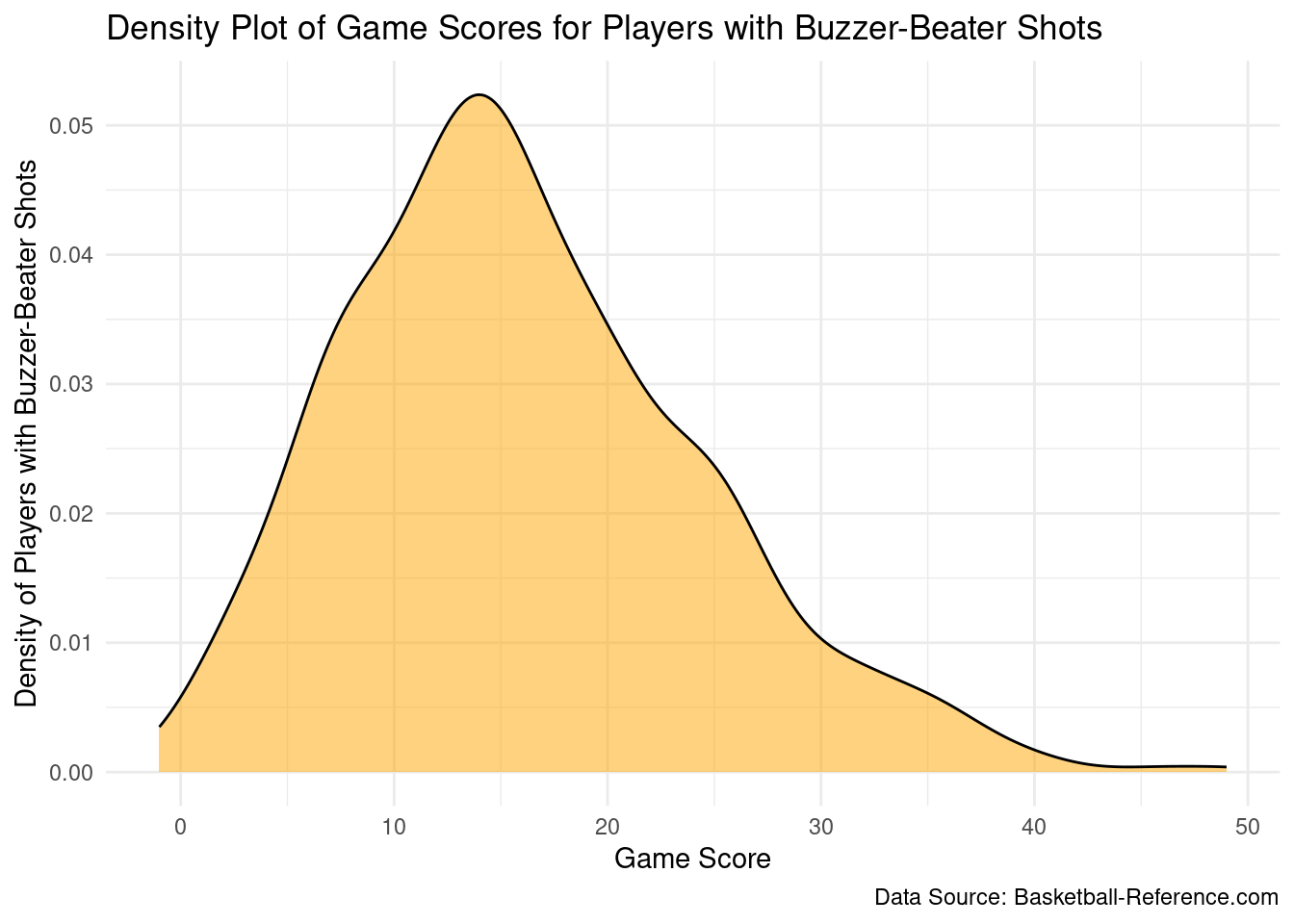
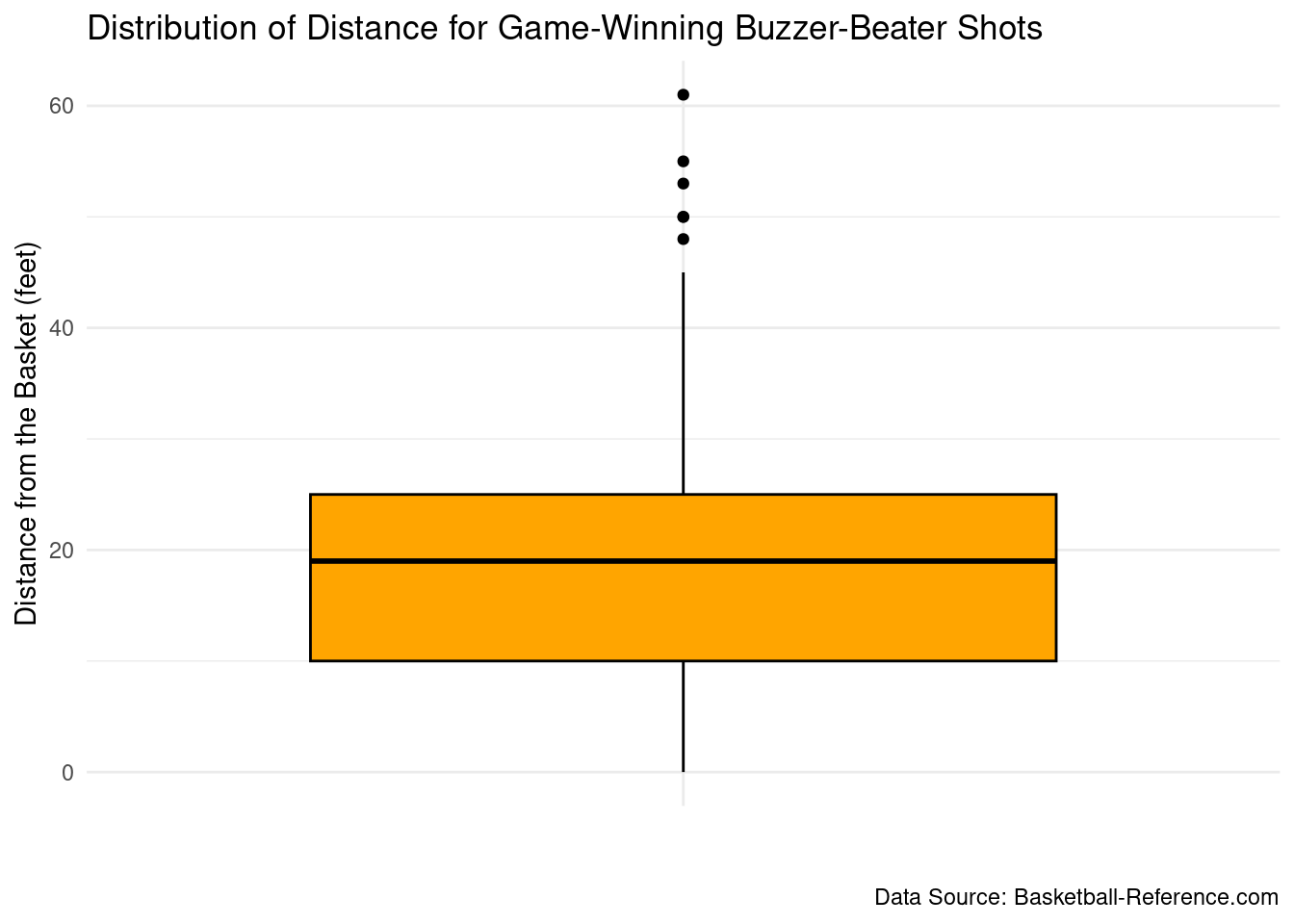
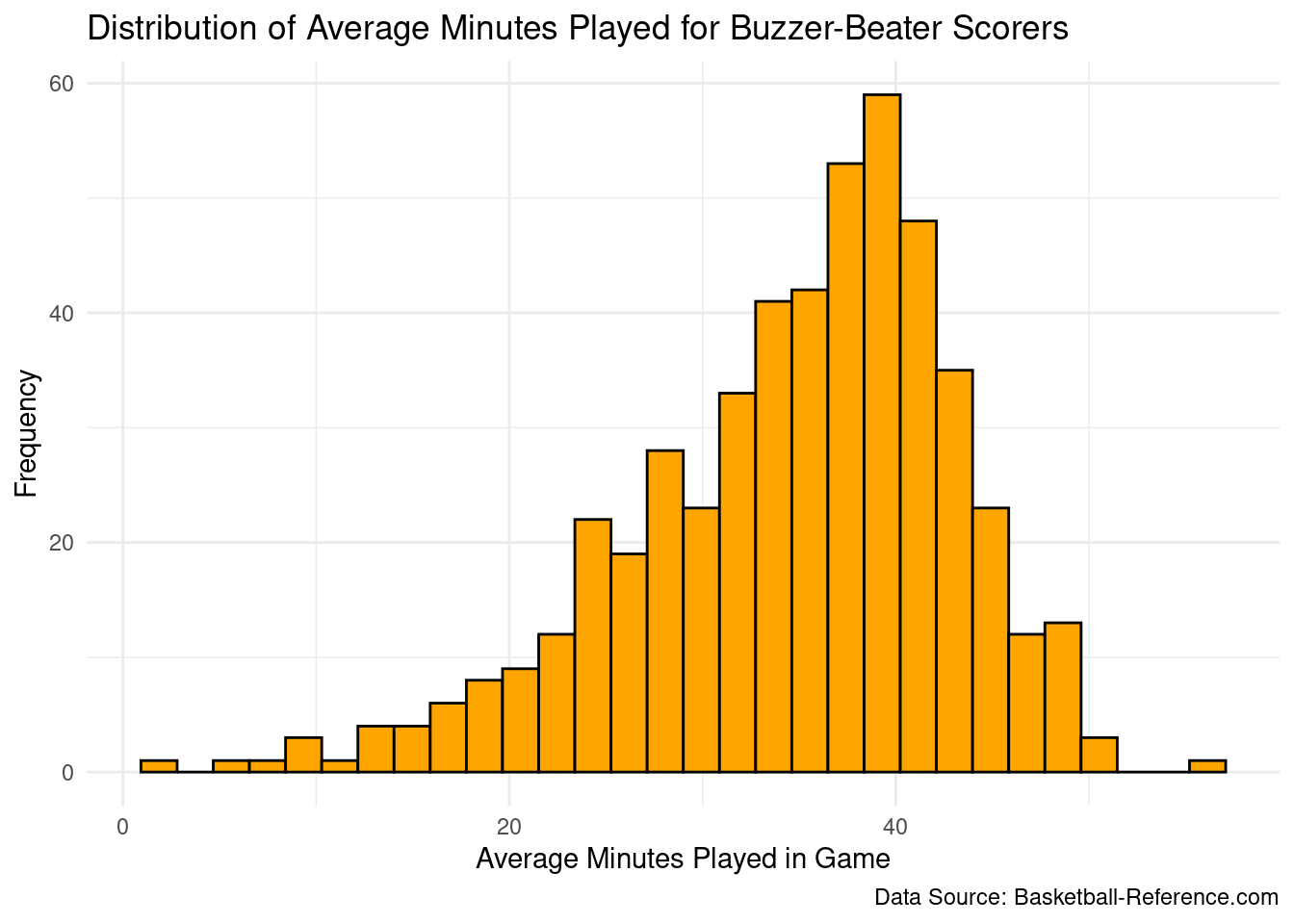
Rows: 822
Columns: 24
$ Player <chr> "Daniel Gafford", "Trae Young ", "Wendell Carter Jr.", "Sadd…
$ Game <chr> "Mar 7 2023", "Feb 26 2023", "Feb 23 2023", "Jan 4 2023", "Ja…
$ Team <chr> "WAS", "ATL", "ORL", "DET", "GSW", "MIA", "CHI", "OKC", "BRK"…
$ Opp <chr> "DET", "BRK", "DET", "GSW", "ATL", "UTA", "ATL", "POR", "TOR"…
$ Margin <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, -1, -2, 0, 0, 0, 0, -1, -1, -2, -1…
$ Type <chr> "2-pt FG", "2-pt FG", "2-pt FG", "3-pt FG", "2-pt FG", "3-pt …
$ Assisted <chr> "unassisted", "unassisted", "unassisted", "K. Hayes", "unassi…
$ Distance <dbl> 0, 12, 0, 28, 0, 25, 0, 14, 27, 6, 25, 1, 23, 31, 13, 0, 26, …
$ MP <chr> "24:38:00", "33:48:00", "31:46:00", "28:46:00", "32:25:00", "…
$ PTS <int> 8, 34, 14, 17, 14, 29, 9, 35, 32, 17, 12, 17, 12, 37, 30, 31,…
$ FG <int> 4, 12, 5, 6, 4, 10, 4, 10, 13, 7, 4, 8, 3, 14, 10, 9, 6, 11, …
$ FGA <int> 5, 26, 13, 17, 8, 20, 6, 24, 22, 17, 8, 15, 5, 24, 17, 18, 14…
$ FG. <dbl> 0.800, 0.462, 0.385, 0.353, 0.500, 0.500, 0.667, 0.417, 0.591…
$ X3P <int> 0, 1, 0, 4, 0, 3, 1, 1, 3, 2, 4, 1, 1, 2, 1, 3, 2, 9, 4, 2, 4…
$ X3PA <int> 0, 5, 3, 10, 0, 11, 3, 1, 9, 11, 7, 6, 3, 7, 3, 7, 6, 12, 5, …
$ X3P. <dbl> NA, 0.200, 0.000, 0.400, NA, 0.273, 0.333, 1.000, 0.333, 0.18…
$ FT <int> 0, 9, 4, 1, 6, 6, 0, 14, 3, 1, 0, 0, 5, 7, 9, 10, 8, 7, 2, 3,…
$ FTA <int> 0, 9, 6, 1, 8, 7, 0, 14, 3, 1, 0, 0, 7, 7, 11, 12, 8, 8, 2, 3…
$ FT. <dbl> NA, 1.000, 0.667, 1.000, 0.750, 0.857, NA, 1.000, 1.000, 1.00…
$ TRB <int> 7, 3, 14, 3, 20, 9, 3, 2, 3, 2, 4, 5, 9, 5, 2, 4, 4, 2, 8, 4,…
$ AST <int> 1, 8, 2, 1, 4, 6, 2, 6, 5, 2, 1, 1, 8, 3, 5, 8, 3, 0, 3, 6, 1…
$ STL <int> 1, 2, 1, 2, 0, 2, 2, 1, 0, 0, 1, 1, 2, 1, 0, 1, 3, 1, 2, 0, 1…
$ BLK <int> 1, 0, 2, 0, 1, 0, 0, 2, 0, 1, 2, 1, 0, 0, 1, 2, 0, 0, 0, 0, 1…
$ GmSc <dbl> 7.8, 24.7, 14.3, 11.1, 21.1, 20.9, 9.3, 26.6, 24.0, 8.8, 9.1,…