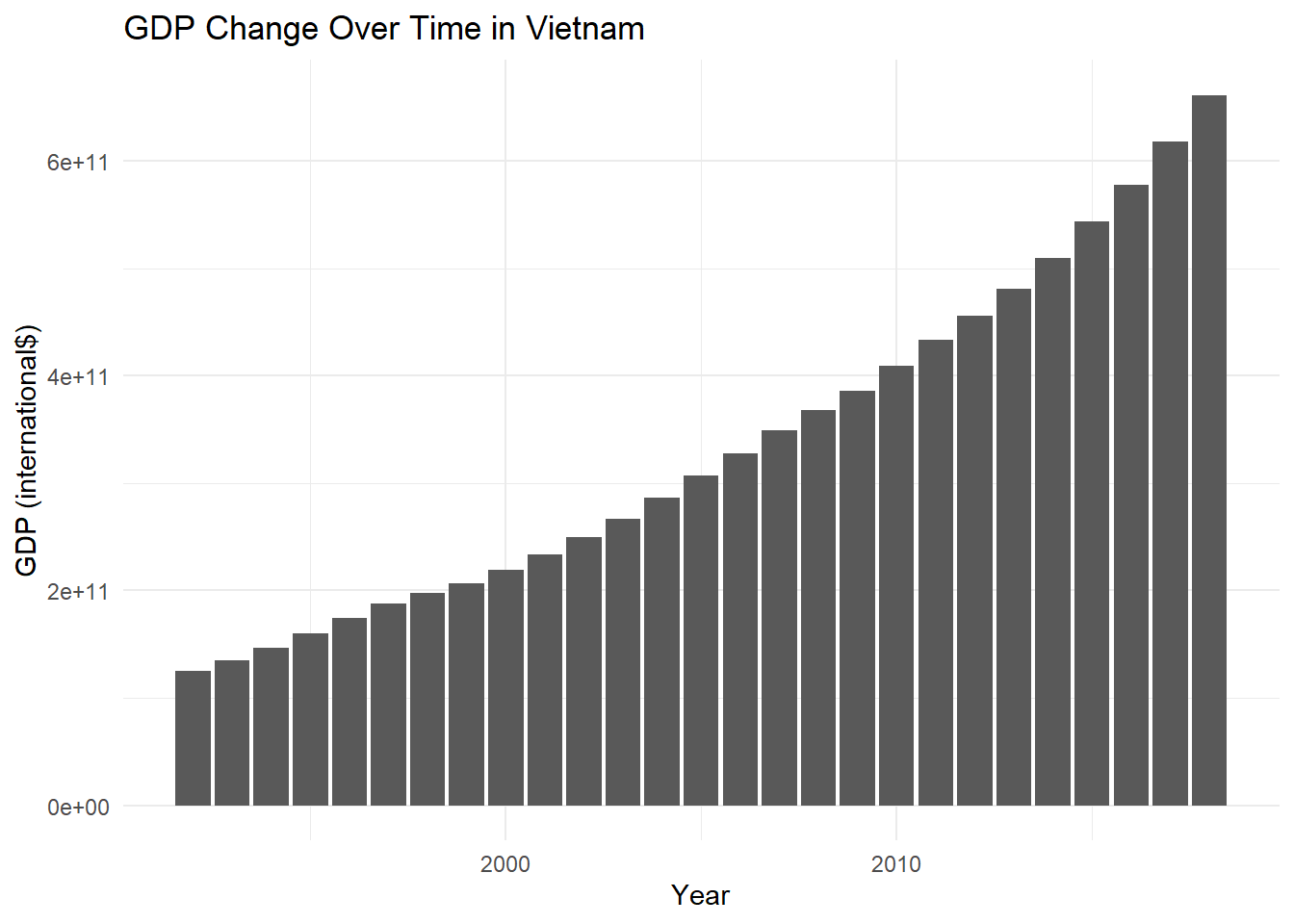
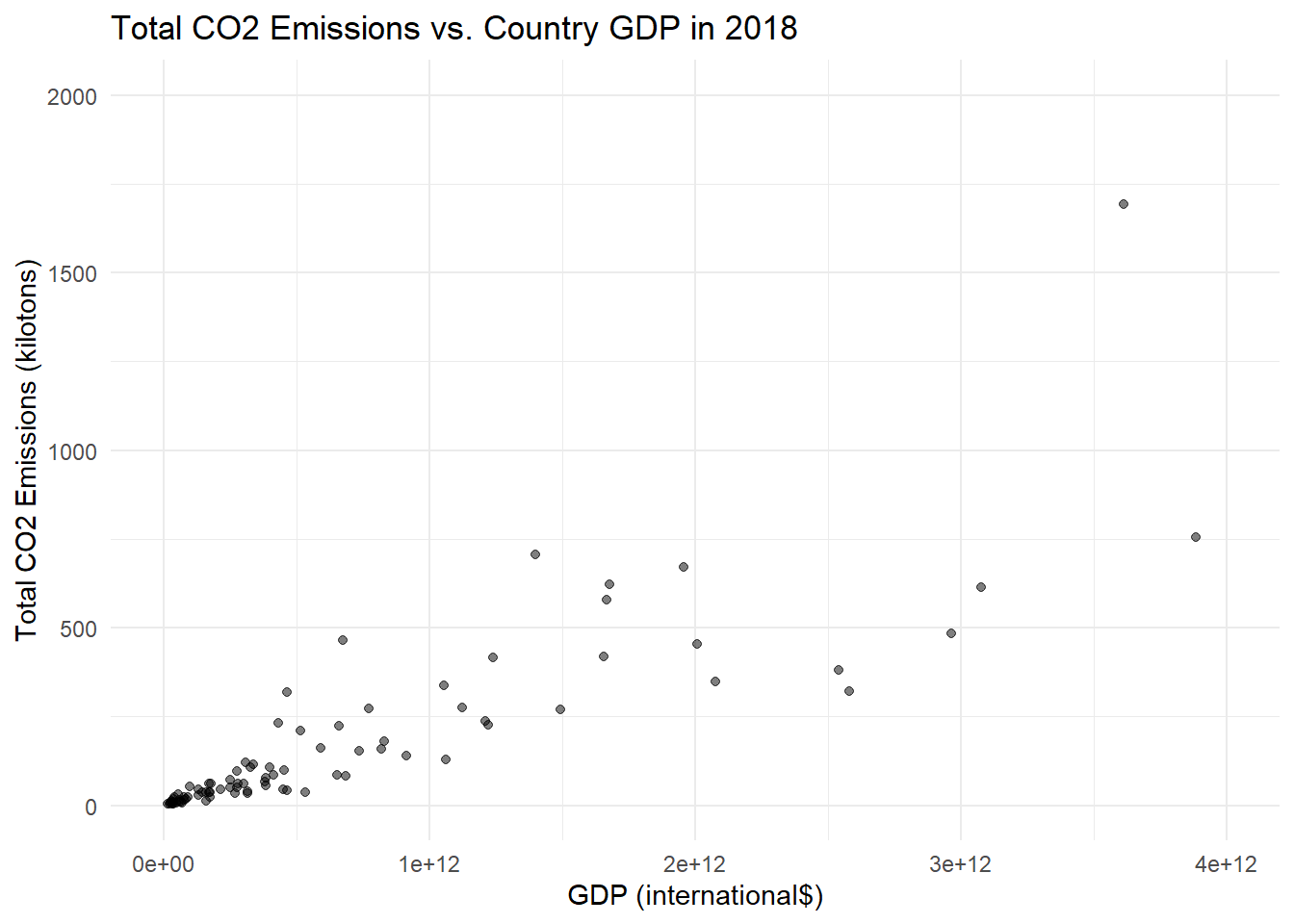
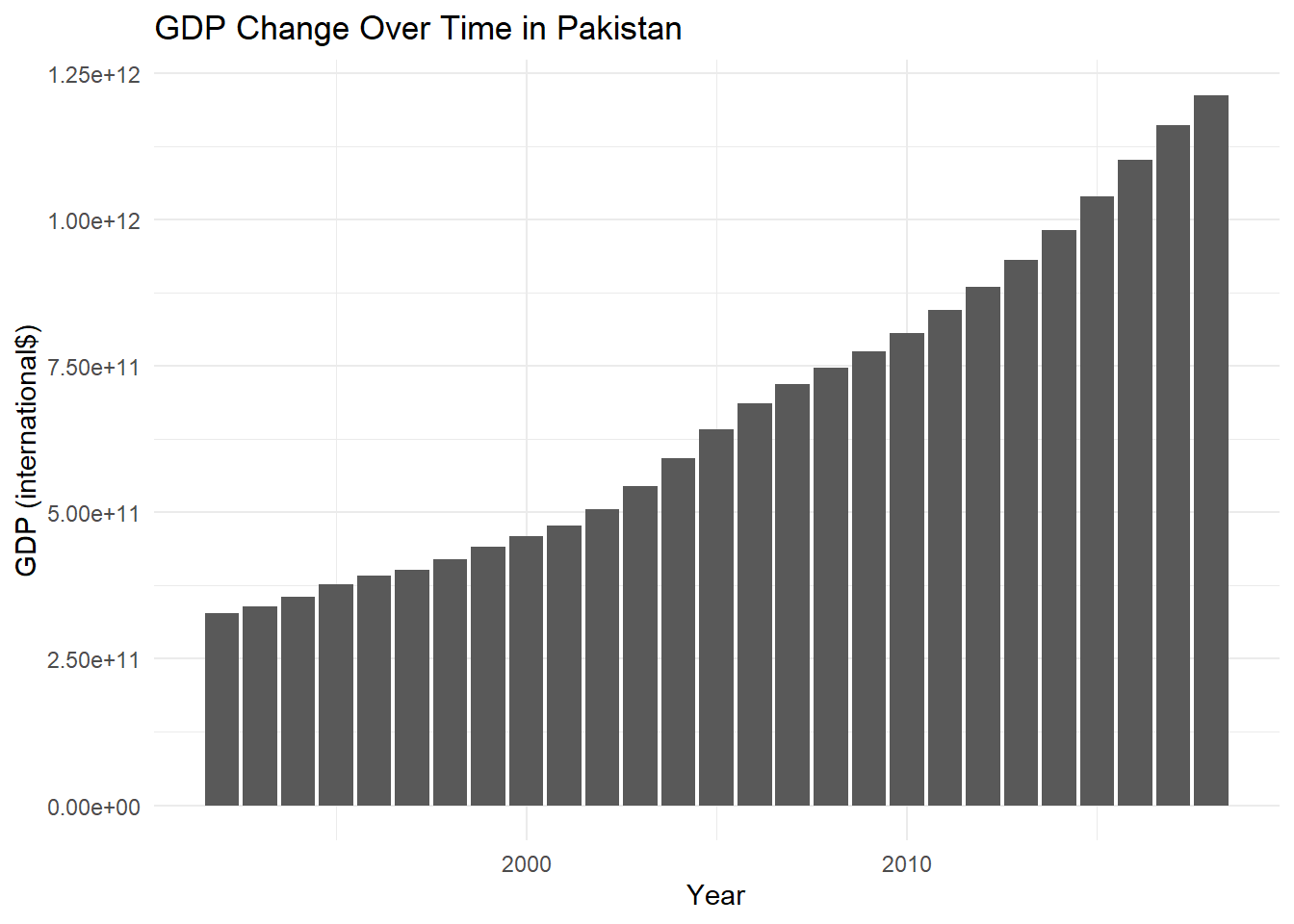Rows: 2,484
Columns: 20
$ Year <dbl> 1992, 1993, 1994, 1995, 1996, 199…
$ Country.Name <chr> "Afghanistan", "Afghanistan", "Af…
$ Country.Code <chr> "AFG", "AFG", "AFG", "AFG", "AFG"…
$ Country.GDP <dbl> 12677538816, 9834580992, 79198571…
$ Country.Population <dbl> 14485543, 15816601, 17075728, 181…
$ Emissions.Production.CH4 <dbl> 7.13, 7.21, 7.47, 7.83, 8.67, 9.4…
$ Emissions.Production.N2O <dbl> 2.89, 2.93, 2.76, 2.88, 3.12, 3.4…
$ Emissions.Production.CO2.Cement <dbl> 0.046, 0.047, 0.047, 0.047, 0.047…
$ Emissions.Production.CO2.Coal <dbl> 0.022, 0.018, 0.015, 0.015, 0.007…
$ Emissions.Production.CO2.Gas <dbl> 0.363, 0.352, 0.338, 0.322, 0.308…
$ Emissions.Production.CO2.Oil <dbl> 0.927, 0.894, 0.860, 0.824, 0.780…
$ Emissions.Production.CO2.Flaring <dbl> 0.022, 0.022, 0.022, 0.022, 0.022…
$ Emissions.Production.CO2.Other <dbl> 0.000000e+00, 0.000000e+00, 2.220…
$ Emissions.Production.CO2.Total <dbl> 1.379, 1.333, 1.282, 1.230, 1.165…
$ `Emissions.Global Share.CO2.Cement` <dbl> 0.01, 0.01, 0.01, 0.01, 0.01, 0.0…
$ `Emissions.Global Share.CO2.Coal` <dbl> 0.00, 0.00, 0.00, 0.00, 0.00, 0.0…
$ `Emissions.Global Share.CO2.Gas` <dbl> 0.01, 0.01, 0.01, 0.01, 0.01, 0.0…
$ `Emissions.Global Share.CO2.Oil` <dbl> 0.01, 0.01, 0.01, 0.01, 0.01, 0.0…
$ `Emissions.Global Share.CO2.Flaring` <dbl> 0.01, 0.01, 0.01, 0.01, 0.01, 0.0…
$ `Emissions.Global Share.CO2.Total` <dbl> 0.01, 0.01, 0.01, 0.01, 0.00, 0.0…