# A tibble: 1,845 × 12
id city region first_choice second_choice would_not_use gender race
<dbl> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 1856261 FL Palm Ci… Disgust Surprise Happiness female white
2 29885393 LA Lake Ch… Fear Surprise Happiness female white
3 6432269 OH Macedon… Sadness Anger Happiness female white
4 4316379 NY Bronx Happiness Neutral Anger female white
5 45264713 FL Miami Happiness Neutral Sadness female lati…
6 9559045 OK Jenks Happiness Happiness Anger female white
7 44044795 AZ Lake Ha… Fear Sadness Happiness male white
8 27215203 OK Tulsa Disgust Fear Happiness female other
9 44788207 FL Altamon… Surprise Fear Happiness male black
10 37243882 IA Perry Happiness Happiness Anger male white
# ℹ 1,835 more rows
# ℹ 4 more variables: target <chr>, emotion <chr>, image_race <chr>,
# image_gender <chr>
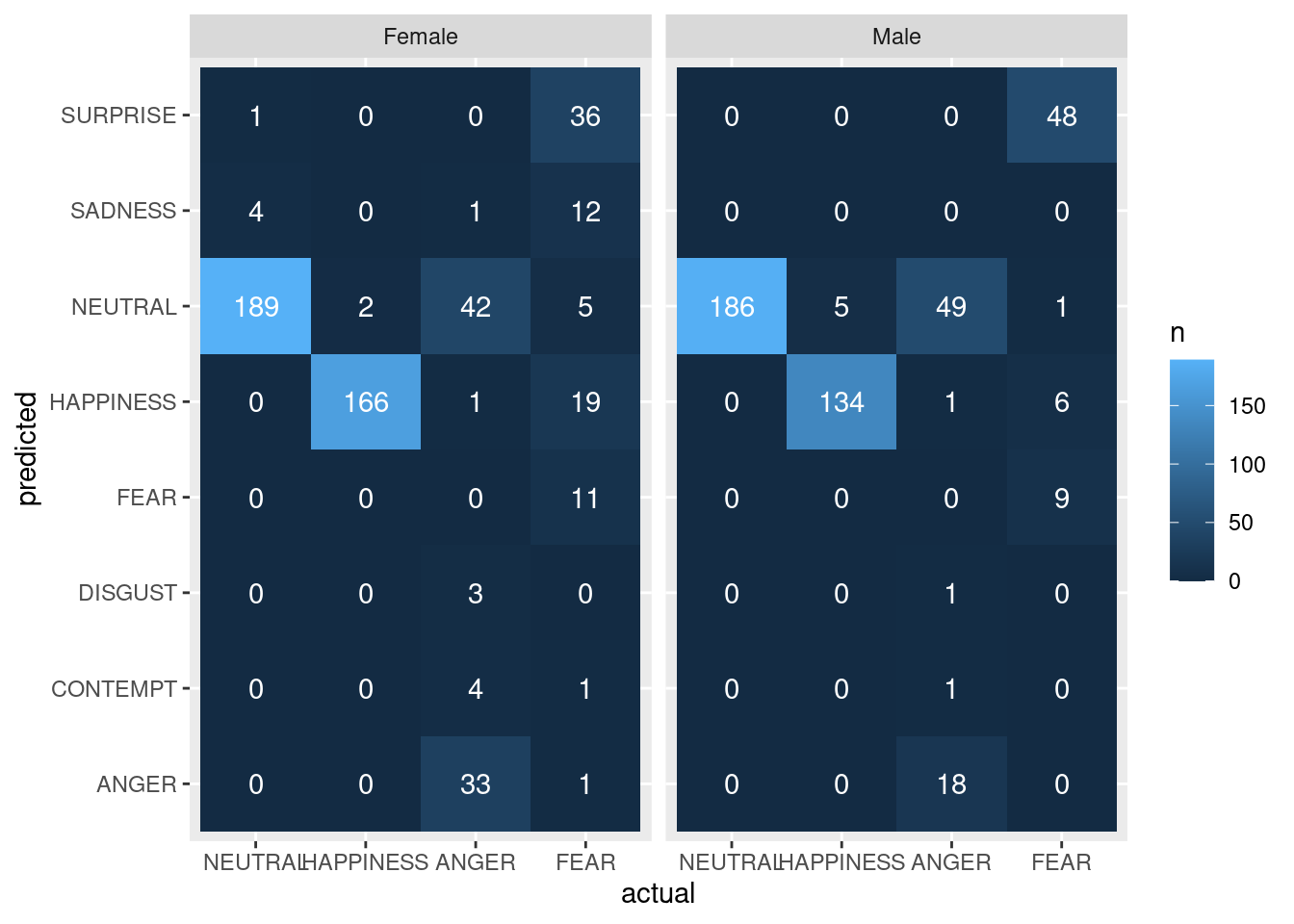
These code chunks show the results from analyzing gender and exploring if there is any gender bias. Interestingly, the pvalues showed that there is a significant difference in the guessing accuracy for the emotion “fear” in females compared to males(pvalue = 0.00085). Fear is often confused with surprise and happinessin females. Although these findings are interesting, they are not very relevant to our study.
res <-data.frame()for (cat inunique(df$actual)){ cur <- df |>filter(actual == cat, race %in%c('Black', 'White')) comp <-chisq.test(table(cur$gender, cur$predicted)) res <-bind_rows(res, data.frame(category=cat, statisitcs=comp$statistic, pvalue=comp$p.value))}
Warning in chisq.test(table(cur$gender, cur$predicted)): Chi-squared
approximation may be incorrect
Warning in chisq.test(table(cur$gender, cur$predicted)): Chi-squared
approximation may be incorrect
Warning in chisq.test(table(cur$gender, cur$predicted)): Chi-squared
approximation may be incorrect
Warning in chisq.test(table(cur$gender, cur$predicted)): Chi-squared
approximation may be incorrect
res <- res |> tibble::rownames_to_column() |>select(-rowname)res