Loading required package: timechange
Attaching package: 'lubridate'
The following objects are masked from 'package:base':
date, intersect, setdiff, union
library(tidyr)
Research question(s)
How have individual team performances(ratings) fluctuated over time? Which NFL teams have been the most or least successful throughout NFL history?
How well does this ELO rating predict regular season / postseason success?
How much does a quarterback’s ELO score contribute to a team’s overall ELO rating?
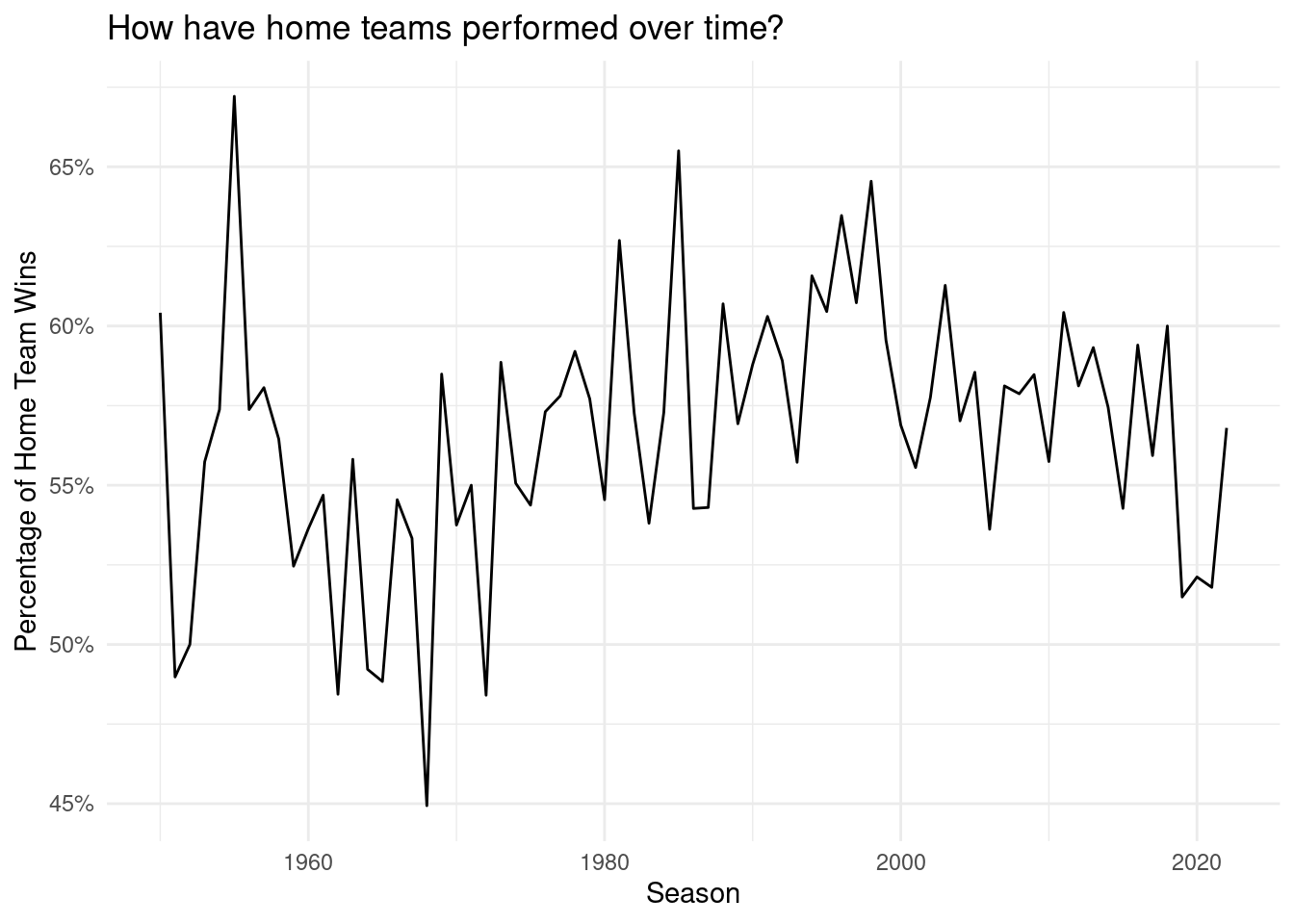
Does having the home field really give a team an advantage? Is this advantage different or more pronounced in the playoffs?
Rows: 17379 Columns: 33
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (5): playoff, team1, team2, qb1, qb2
dbl (27): season, neutral, elo1_pre, elo2_pre, elo_prob1, elo_prob2, elo1_p...
date (1): date
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Filter out teams that are no longer active in the NFL
Add new variable for winning team
Filter years so that only years with all values are included. This is done by filtering for only seasons in 1950 or earlier.
Replace all NA values for the playoff column with “r”.
Remove columns total_rating and importance as these statistics were only recorded starting in 2021 and are not relevant to data analysis.
Break main dataset into smaller datasets for research question. This will allow us to select specific columns that are relevant to each question.
Have an initial draft of your data cleaning appendix. Document every step that takes your raw data file(s) and turns it into the analysis-ready data set that you would submit with your final project. Include text narrative describing your data collection (downloading, scraping, surveys, etc) and any additional data curation/cleaning (merging data frames, filtering, transformations of variables, etc). Include code for data curation/cleaning, but not collection.
Data description
We analyzed the NFL Elo dataset provided by FiveThirtyEight, which contains historical data on NFL games and Elo ratings for each team. The dataset covers games from the beginning of the league in 1920 through the 2021 season. Elo ratings are a measure of a team’s strength and are used to predict the outcome of games based on each team’s relative skill level.
In addition to the Elo ratings, the dataset includes information about the game date, season, teams involved, where the game is played, playoff status, and the actual scores for each team. The dataset also contains advanced statistics such as quarterback Elo ratings.
Our focus is to analyze how a team’s Elo rating can predict their winning probability during the regular season, playoffs, and Super Bowl. In doing so, we will consider additional factors such as the location of the game and the quarterback ratings. By incorporating these elements, we aim to gain a deeper understanding of the factors influencing game outcomes, allowing us to draw more informed and nuanced conclusions.
Data limitations
The dataset does include ELO values as well as other relevant information needed to address the majority of the research questions. One of the research questions pertains to finding the contribution of a quarterback’s ELO score to a team’s overall ELO rating. It is easier to establish a correlative relationship and more difficult to use the data to prove the extent of contribution. In this way, it is challenging to precisely answer the research question with the data. Otherwise, it seems plausible to address the remaining research questions with the dataset.
Exploratory data analysis
nfl_data_homewins <- nfl_data_clean |>group_by(season) |>summarize(pct_home_win =sum(home_win ==TRUE) /n())ggplot(nfl_data_homewins, aes(x = season, y = pct_home_win)) +geom_line() +theme_minimal() +labs(x ="Season",y ="Percentage of Home Team Wins",title ="How have home teams performed over time?" ) +scale_y_continuous(labels =label_percent())
Questions for reviewers
List specific questions for your peer reviewers and project mentor to answer in giving you feedback on this phase.
Do 4 research questions seem holistic for the research and research goal?
How to minimize the negative impact caused by the limitation of dataset?