Rows: 538
Columns: 12
$ name <chr> "Bill Gates", "Warren Buffett", "Paul Allen"…
$ demographics.age <int> 45, 70, 48, 56, NA, 44, 53, 55, 57, 52, 81, …
$ location.citizenship <chr> "United States", "United States", "United St…
$ location.gdp <dbl> 1.06e+13, 1.06e+13, 1.06e+13, 1.06e+13, 1.95…
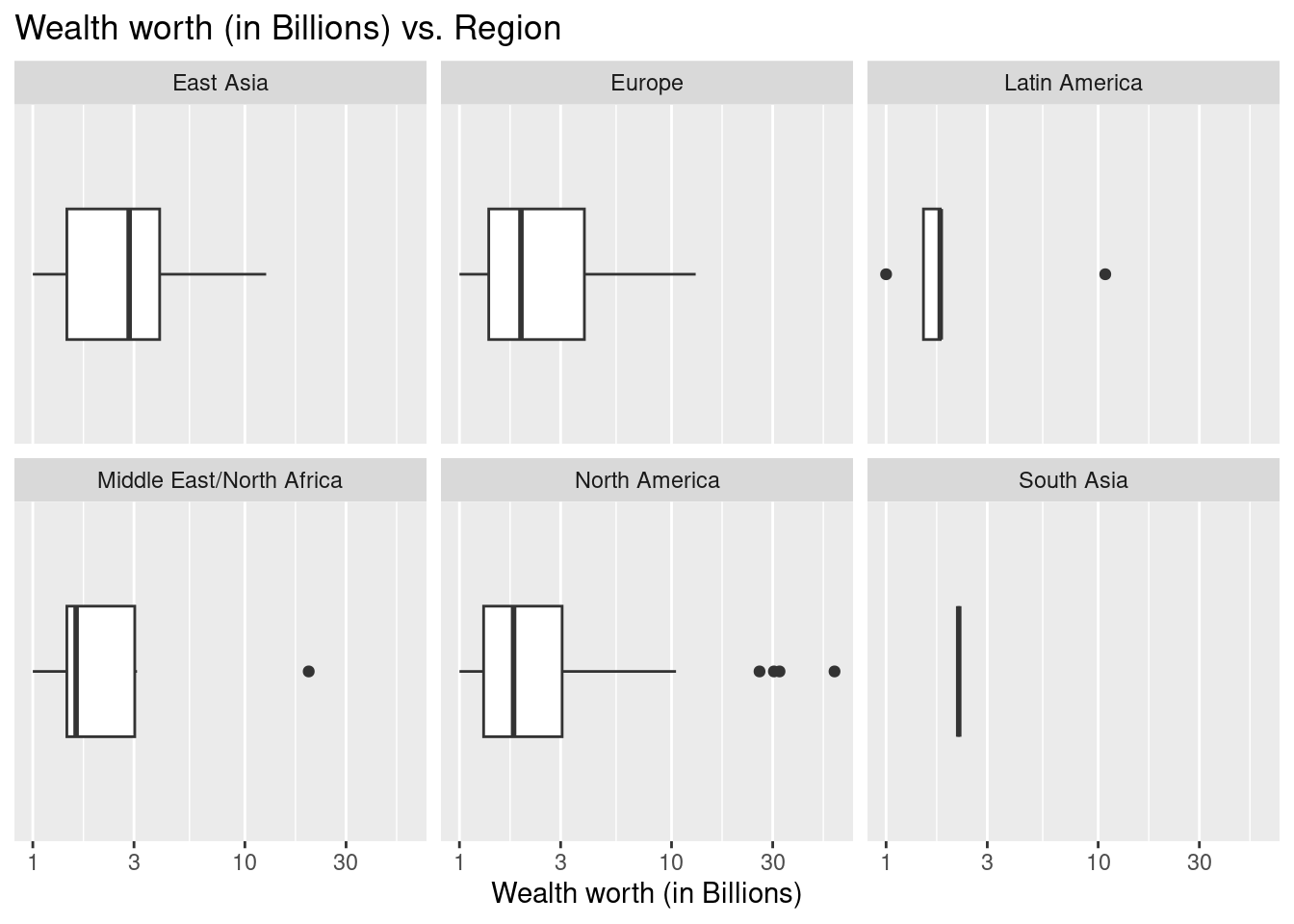
$ location.region <chr> "North America", "North America", "North Ame…
$ location.country.code <chr> "USA", "USA", "USA", "USA", "DEU", "SAU", "U…
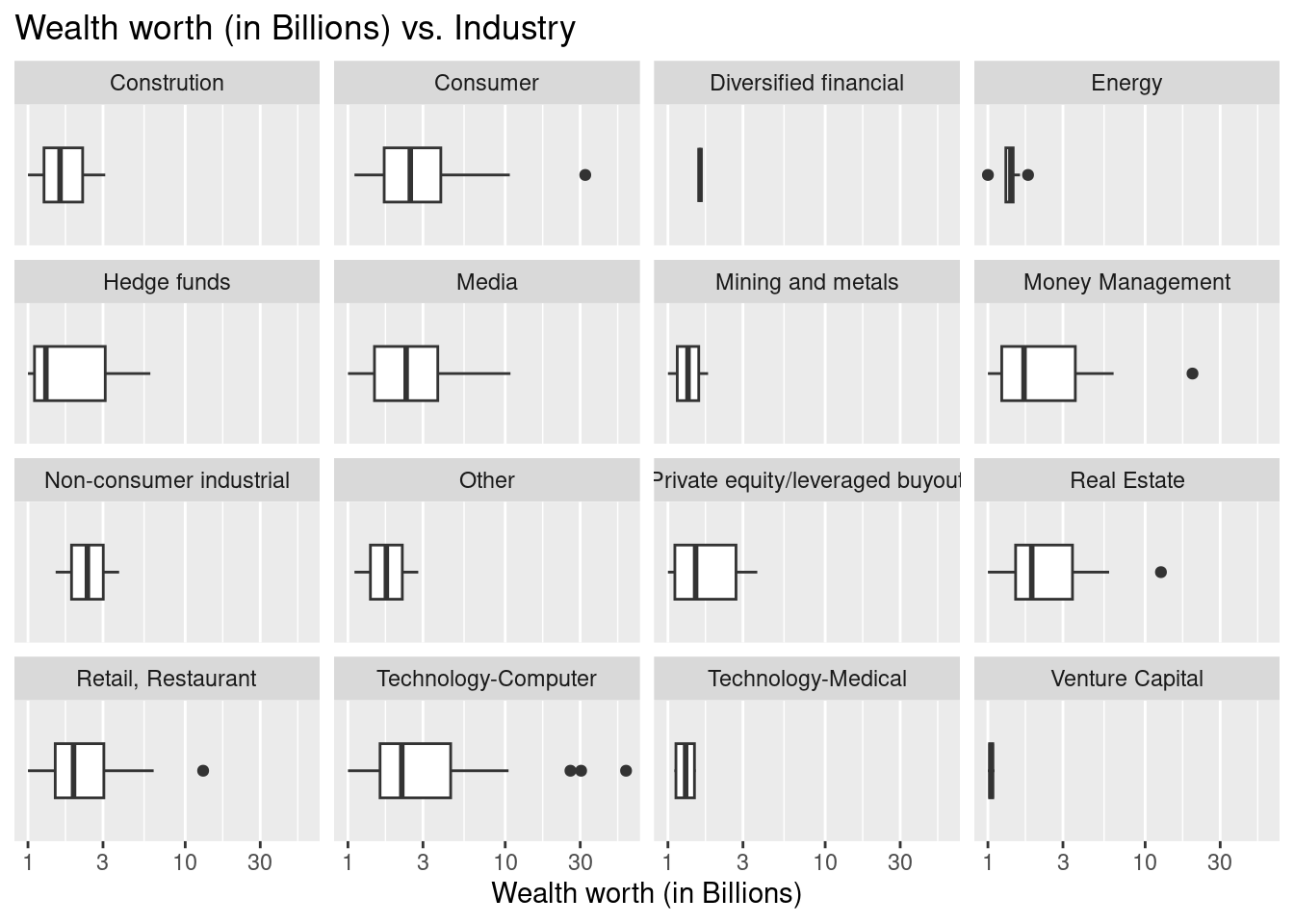
$ wealth.worth.in.billions <dbl> 58.7, 32.3, 30.4, 26.0, 25.0, 20.0, 18.8, 18…
$ wealth.how.industry <chr> "Technology-Computer", "Consumer", "Technolo…
$ wealth.how.inherited <chr> "not inherited", "not inherited", "not inher…
$ age.when.founded.company <dbl> 19, 31, 22, 32, NA, 23, NA, NA, NA, NA, NA, …
$ n <int> 269, 269, 269, 269, 28, 8, 269, 269, 269, 26…
$ location.num.billionaires <int> 269, 269, 269, 269, 28, 8, 269, 269, 269, 26…