Question 1: Is there a relationship between a film’s location and year versus its budget?
Question 2: Which release dates see the greatest profits?
Question 3: How strong is the relationship between a film’s release year and income versus its iMDB rating?
Data collection and cleaning
Have an initial draft of your data cleaning appendix. Document every step that takes your raw data file(s) and turns it into the analysis-ready data set that you would submit with your final project. Include text narrative describing your data collection (downloading, scraping, surveys, etc) and any additional data curation/cleaning (merging data frames, filtering, transformations of variables, etc). Include code for data curation/cleaning, but not collection.
See appendix for more detailed information
library(dplyr)
Attaching package: 'dplyr'
The following objects are masked from 'package:stats':
filter, lag
The following objects are masked from 'package:base':
intersect, setdiff, setequal, union
Rows: 2000 Columns: 13
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (11): Title, Month, Certificate, Runtime, Directors, Stars, Genre, Filmi...
dbl (2): Rating, Year
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
# Make all column names lowercasenames(movies) <-tolower(names(movies))# Replace "Unknown" strings with NA for data analysismovies <- movies |>mutate(income =na_if(income, "Unknown"),budget =na_if(budget, "Unknown") )# Remove all films with NA values for income or budgetmovies <- movies |>filter(is.na(income) ==FALSE&is.na(budget) ==FALSE)# Split genremovies <- movies |>mutate(genre =str_split(string = genre, pattern =","),directors =str_split(string = directors, pattern =","),stars =str_split(string = stars, pattern =","),country_of_origin =str_split(string = country_of_origin, pattern =","))movies
# A tibble: 1,651 × 13
title rating year month certificate runtime directors stars genre
<chr> <dbl> <dbl> <chr> <chr> <chr> <list> <lis> <lis>
1 Avatar: The Way… 7.8 2022 Dece… PG-13 192 <chr [1]> <chr> <chr>
2 Guillermo del T… 7.6 2022 Dece… PG 117 <chr [2]> <chr> <chr>
3 Bullet Train 7.3 2022 Augu… R 127 <chr [1]> <chr> <chr>
4 M3gan 6.4 2022 Dece… PG-13 102 <chr [1]> <chr> <chr>
5 Amsterdam 6.1 2022 Octo… R 134 <chr [1]> <chr> <chr>
6 Violent Night 6.9 2022 Dece… R 112 <chr [1]> <chr> <chr>
7 The Whale 7.8 2022 Dece… R 117 <chr [1]> <chr> <chr>
8 The Fabelmans 7.6 2022 Nove… PG-13 151 <chr [1]> <chr> <chr>
9 The Menu 7.5 2022 Nove… R 107 <chr [1]> <chr> <chr>
10 Babylon 7.3 2022 Dece… R 188 <chr [1]> <chr> <chr>
# ℹ 1,641 more rows
# ℹ 4 more variables: filming_location <chr>, budget <chr>, income <chr>,
# country_of_origin <list>
Data description
**• What are the observations (rows) and the attributes (columns)?**
The atttributes or variables in our dataset represent movies. Specifically, our variables are the movie title, iMDB rating, year of release, month of release, certificate, runtime, director(s), stars, genre(s), filming location, budget, income, and country of origin. Each row represents a unique film that has all the above data on iMBD. Note that this data set contains the 100 most popular movies for each year from 2003-2022. There are 1989 rows and 13 columns.
**• Why was this dataset created?**
This data was created on Kaggle for use for exploratory data analysis for anyone on the internet.
**• Who funded the creation of the dataset?**
The dataset was created and uploaded to Kaggle by a user with the username GEORGE SCUTELNICU. Kaggle has licensed this dataset for the public domain.
**• What processes might have influenced what data was observed and recorded and what was not?**
Since the data was web scraped from the iMDB website, processes that would have influenced what data was observed and recorded and not would largely be the iMDB policy. It is possible that certain kinds of movies or certain controversial directors or stars are forbidden from appearing on their search history. Hence, certain movies might have been exempt from the data on their website. Moreover, since the dataset consists of 100 movies from every year from 2003-2022, the data can be influenced based on how ‘popularity’ is being measured by iMDB.
**• What preprocessing was done, and how did the data come to be in the form that you are using?**
The preprocessing that was done was by the user GEORGE SCUTELNICU on Kaggle who created this dataset was mainly web scraping. I assume that there must have been some kind of data rearrangement or filtering to get down to the 13 columns that are there in the final dataset. There might also have been some dropping of observations with missing values. I note this because we should expect 20*100 = 2000 movies since there are 20 years and 100 movies each year. However, we have only 1989 observations. So, there must be some missing values.
**• If people are involved, were they aware of the data collection and if so, what purpose did they expect the data to be used for?**
Yes, this data was collected intentionally. The purpose listed on the website was for exploratory data analysis for anyone on the internet who came across the data set (hence, it has been licensed for use by the public).
**• Is the dataset self-contained, or does it link to or otherwise rely on external resources (e.g., websites, tweets, other datasets)?**
A quick look at the data shows that it is indeed self-contained. None of the entries in the dataset refer to any other website or any other dataset. All entires are alphanumeric entires.
**• Does the dataset contain data that might be considered confidential (e.g., data that is protected by legal privilege or by doctor--patient confidentiality, data that includes the content of individuals' non-public communications)?**
No, the dataset does not consider any data that is considered confidential. As already stated above, this dataset was created by the user GEORGE SCUTELNICU on Kaggle for the purpose of exploratory data analysis and has been licensed on Kaggle for free use to the public without any copyright issues.
**• Has the dataset been used for any tasks already?**
Since the dataset is available for public use on Kaggle, it is possible that the data has already been used for other tasks by other individuals.
**• Is there a repository that links to any or all papers or systems that use the dataset?**
Yes, the link to the Kaggle site where this dataset is available might have information on which users or how many users have used this dataset before. It also tracks when the dataset was last updated, which at the time this assignment was submitted was March 15, 2023. Link to the dataset: https://www.kaggle.com/datasets/georgescutelnicu/top-100-popular-movies-from-2003-to-2022-imdb (https://www.kaggle.com/datasets/georgescutelnicu/top-100-popular-movies-from-2003-to-2022-imdb)
Data limitations
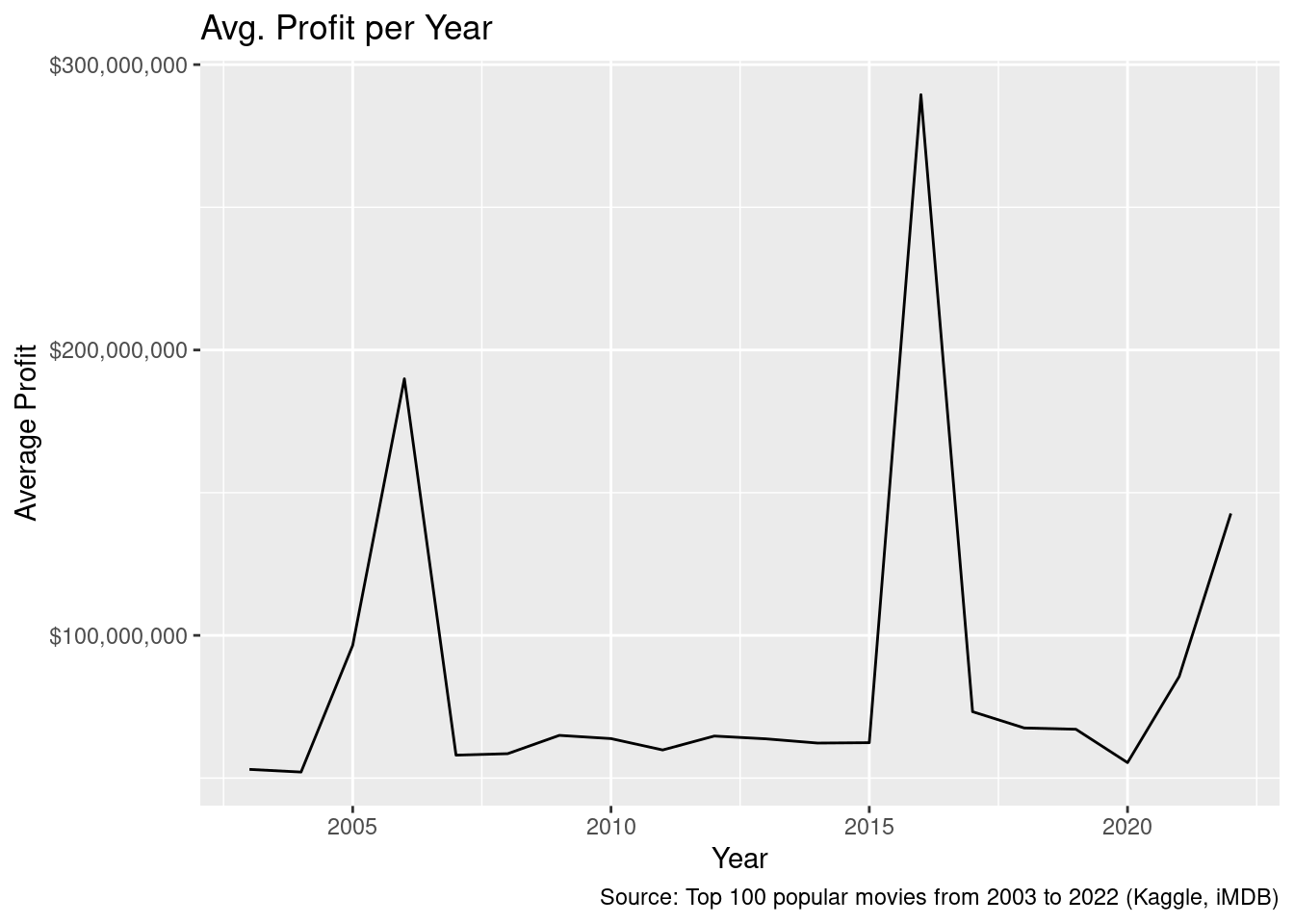
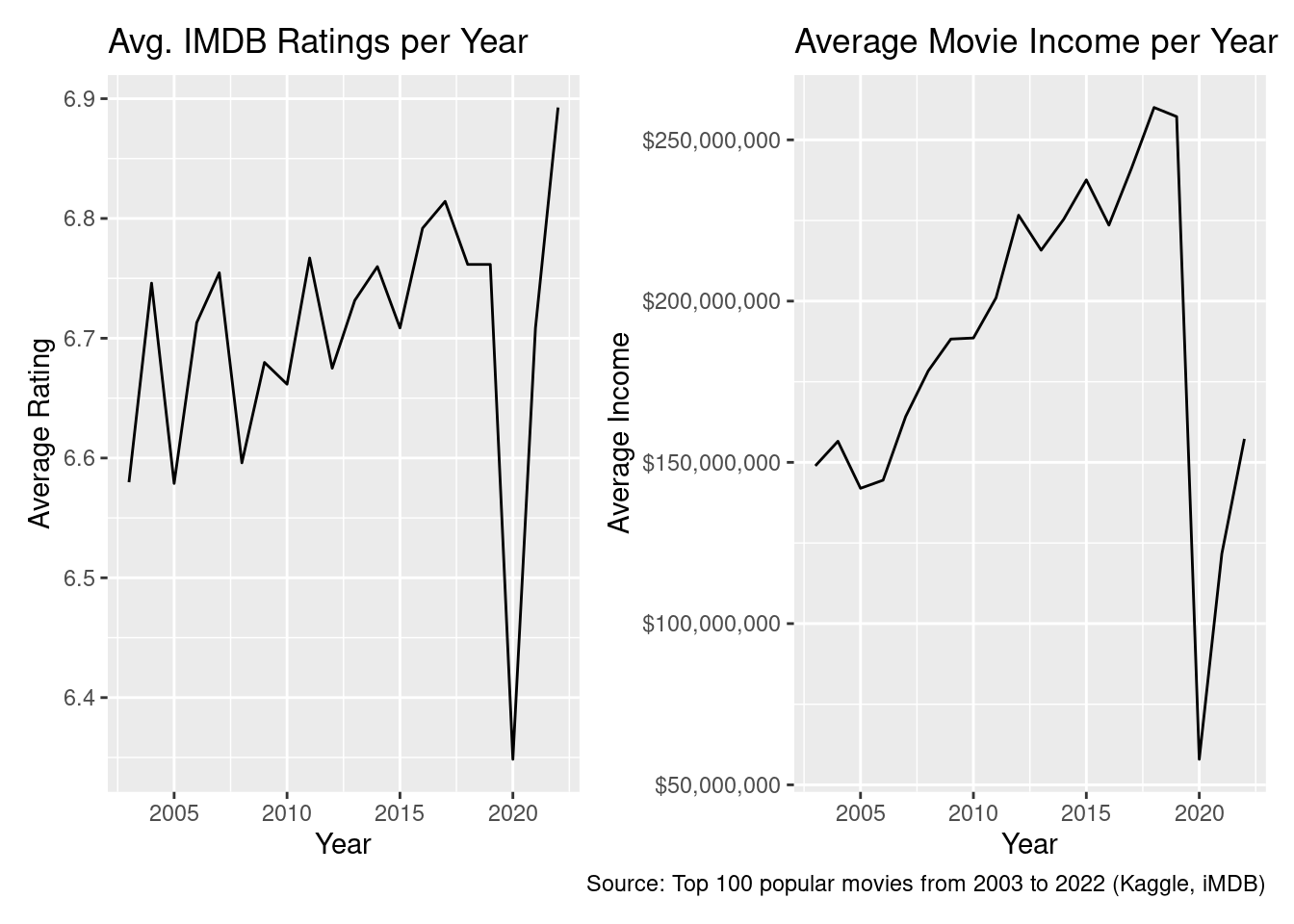
Some data limitations is that because this data is based on the way iMDB scores popularity, it may not necessarily reflect how other sites or how others may think of a movie in terms of ranking and popularity. Thus, the data could be biased. In addition, some of the data has columns that are missing. For example, not all the certificates have correlated values (34 certificates are missing). Another possible limitation is that if we were to use categories regarding budget or income, there are certain movies that have a missing budget or income. Finally, the data for income and ratings seems to be quite low in 2020, presumably because of the pandemic—movies received lower income and lower ratings, so COVID-19 likely presents a confounding variable for our analysis, especially when mapping changes in income/ratings over time.
Rows: 2000 Columns: 13
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (11): Title, Month, Certificate, Runtime, Directors, Stars, Genre, Filmi...
dbl (2): Rating, Year
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
movies |>filter(Budget !="Unknown") |>mutate(Budget =parse_number(Budget)) |>select(Budget, Filming_location) |>group_by(Filming_location) |>summarize(avg_budget =mean(Budget))
# A tibble: 96 × 2
Filming_location avg_budget
<chr> <dbl>
1 Arctic Ocean 165000000
2 Argentina 95900000
3 Australia 84351053.
4 Austria 54566667.
5 Bahamas 19833333.
6 Bangladesh 157500000
7 Belgium 27980000
8 Bolivia 317000000
9 Brazil 85000000
10 Bulgaria 277635077.
# ℹ 86 more rows
movies |>filter(Income !="Unknown") |>mutate(Income =parse_number(Income)) |>filter(Budget !="Unknown") |>mutate(Budget =parse_number(Budget)) |>select(Year, Income, Budget) |>mutate(Profit = Income - Budget) |>group_by(Year) |>summarize(avg_profit =mean(Budget)) |>ggplot(aes(x = Year, y = avg_profit)) +scale_y_continuous(labels =label_dollar()) +geom_line() +labs(x ='Year',y ='Average Profit',title ='Avg. Profit per Year',caption ="Source: Top 100 popular movies from 2003 to 2022 (Kaggle, iMDB)" )
p1 <- movies |>filter(Income !="Unknown") |>mutate(Income =parse_number(Income)) |>select(Year, Income, Rating) |>group_by(Year) |>summarize(avg_income =mean(Income), avg_rating =mean(Rating)) |>ggplot(aes(x= Year, y = avg_rating)) +geom_line() +labs(x ='Year',y ='Average Rating',title ='Avg. IMDB Ratings per Year' )p2 <- movies |>filter(Income !="Unknown") |>mutate(Income =parse_number(Income)) |>select(Year, Income, Rating) |>group_by(Year) |>summarize(avg_income =mean(Income), avg_rating =mean(Rating)) |>ggplot(aes(x= Year, y = avg_income)) +geom_line() +scale_y_continuous(labels =label_dollar()) +labs(x ='Year',y ='Average Income',title ='Average Movie Income per Year',caption ="Source: Top 100 popular movies from 2003 to 2022 (Kaggle, iMDB)" )p1 + p2 +plot_layout(ncol =2)
Questions for reviewers
Is there a specific research question that you think would be more interesting the others?
Do you think there should be a different way we do data cleaning/or a way for us to improve upon our methodologies?
What do you think we could do to further improve our exploratory data analysis?
How can we incorporate more complex techniques (machine learning, web scraping, etc.) into our project?
How should we account for the outlier rating and income values in 2020 because of the pandemic? Should we exclude this data from our analysis?