How does mental health diagnosis vary by race? Is there correlation between an individual’s race and mental health diagnosis?
Does there exist an interaction between race and - age, education, ethnicity, gender, substance use, veteran status, or state resided in - that influences an individual’s mental health diagnosis?
Data collection and cleaning
Have an initial draft of your data cleaning appendix. Document every step that takes your raw data file(s) and turns it into the analysis-ready data set that you would submit with your final project. Include text narrative describing your data collection (downloading, scraping, surveys, etc) and any additional data curation/cleaning (merging data frames, filtering, transformations of variables, etc). Include code for data curation/cleaning, but not collection.
Loading required package: airports
Loading required package: cherryblossom
Loading required package: usdata
Attaching package: 'openintro'
The following object is masked from 'package:modeldata':
ames
library(skimr)library(janitor)
Attaching package: 'janitor'
The following objects are masked from 'package:stats':
chisq.test, fisher.test
library(viridis)
Loading required package: viridisLite
Attaching package: 'viridis'
The following object is masked from 'package:scales':
viridis_pal
age <-read_csv("data/Final_Data/AGE x MH1.csv")
Rows: 240 Columns: 17
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (13): Age (recoded), Mental health diagnosis one, Total % SE, Total % CI...
dbl (4): Total %, Row %, Column %, Unweighted Count
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
education <-read_csv("data/Final_Data/EDUC x MH1.csv")
Rows: 105 Columns: 17
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (13): Education, Mental health diagnosis one, Total % SE, Total % CI (lo...
dbl (4): Total %, Row %, Column %, Unweighted Count
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
ethnicity <-read_csv("data/Final_Data/ETHNIC x MH1.csv")
Rows: 90 Columns: 17
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (13): Hispanic or Latino origin (ethnicity), Mental health diagnosis one...
dbl (4): Total %, Row %, Column %, Unweighted Count
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
gender <-read_csv("data/Final_Data/GENDER x MH1.csv")
Rows: 60 Columns: 17
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (13): Sex, Mental health diagnosis one, Total % SE, Total % CI (lower), ...
dbl (4): Total %, Row %, Column %, Unweighted Count
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
race <-read_csv("data/Final_Data/RACE x MH1.csv")
Rows: 120 Columns: 17
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (13): Race, Mental health diagnosis one, Total % SE, Total % CI (lower),...
dbl (4): Total %, Row %, Column %, Unweighted Count
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
substance <-read_csv("data/Final_Data/SUB x MH1.csv")
Rows: 225 Columns: 17
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (13): Substance use diagnosis, Mental health diagnosis one, Total % SE, ...
dbl (4): Total %, Row %, Column %, Unweighted Count
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
veteran <-read_csv("data/Final_Data/VETERAN x MH1.csv")
Rows: 60 Columns: 17
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (13): Veteran status, Mental health diagnosis one, Total % SE, Total % C...
dbl (4): Total %, Row %, Column %, Unweighted Count
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
state <-read_csv("data/Final_Data/STATEFIP x MH1.csv")
Rows: 750 Columns: 17
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (13): Reporting state code, Mental health diagnosis one, Total % SE, Tot...
dbl (4): Total %, Row %, Column %, Unweighted Count
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Warning: Using an external vector in selections was deprecated in tidyselect 1.1.0.
ℹ Please use `all_of()` or `any_of()` instead.
# Was:
data %>% select(variable_name)
# Now:
data %>% select(all_of(variable_name))
See <https://tidyselect.r-lib.org/reference/faq-external-vector.html>.
education <-pivot_raw(education, "Education")ethnicity <-pivot_raw(ethnicity, "Hispanic or Latino origin (ethnicity)")gender <-pivot_raw(gender, "Sex")race <-pivot_raw(race, "Race")substance <-pivot_raw(substance, "Substance use diagnosis")veteran <-pivot_raw(veteran, "Veteran status")state <-pivot_raw(state, "Reporting state code")
For all of the datasets, the first thing that was done was using the clean_names() function found in the janitor library in order to change the column to follow the name rule when using R.
age_mh1<-read_csv("data/Final_Data/AGE x MH1.csv")
Rows: 240 Columns: 17
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (13): Age (recoded), Mental health diagnosis one, Total % SE, Total % CI...
dbl (4): Total %, Row %, Column %, Unweighted Count
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
#Cleaning data for Age and Mental Health diagnosisage_mh12<-age_mh1|>clean_names()age_mh12
Afterward, we selected the unweighted count, mental health diagnosis, and finally the other Categorical column from the dataset. Afterward, the dataset is then placed through 3 different filter options to remove overall counts that may have been present.
# A tibble: 196 × 3
age_recoded mental_health_diagnosis_one unweighted_count
<chr> <chr> <dbl>
1 0-11 years Missing/unknown/not collected/invalid/no or def… 138457
2 0-11 years Trauma- and stressor-related disorders 234345
3 0-11 years Personality disorders 114
4 0-11 years Schizophrenia or other psychotic disorders 1122
5 0-11 years Alcohol or substance use disorders 213
6 0-11 years Other disorders/conditions 102031
7 0-11 years Anxiety disorders 87236
8 0-11 years Attention deficit/hyperactivity disorder (ADHD) 206601
9 0-11 years Conduct disorders 39658
10 0-11 years Delirium, dementia 341
# ℹ 186 more rows
Then a slice is performed from the second row of the dataset to its end so the first row of useless data can be gotten rid of.The last step is to rename the unweighted_count variable to the count of the Categorical data for the data set.
# A tibble: 195 × 3
age_recoded mental_health_diagnosis_one age_count
<chr> <chr> <dbl>
1 0-11 years Trauma- and stressor-related disorders 234345
2 0-11 years Personality disorders 114
3 0-11 years Schizophrenia or other psychotic disorders 1122
4 0-11 years Alcohol or substance use disorders 213
5 0-11 years Other disorders/conditions 102031
6 0-11 years Anxiety disorders 87236
7 0-11 years Attention deficit/hyperactivity disorder (ADHD) 206601
8 0-11 years Conduct disorders 39658
9 0-11 years Delirium, dementia 341
10 0-11 years Bipolar disorders 2467
# ℹ 185 more rows
Data description
Have an initial draft of your data description section. Your data description should be about your analysis-ready data.
Age - The age section of the Mental Health Clinic level has 15 levels, divided by a range from 0-65 years and older, including a level for missing health data. The count-frequency is recorded as well as the percentage recorded for each age level.
Education - The education section records the highest level of education attained. It is split into 6 different levels, Ranging from special education to More than grade 12, including missing values.
Ethnicity - Records the counts and frequency for patients that are Mexican, Puerto Rican, Other Hispanic or Latino Origin, Not of hispanic/latino origin, or missing/untabulated data. The percentage within the category is also recorded.
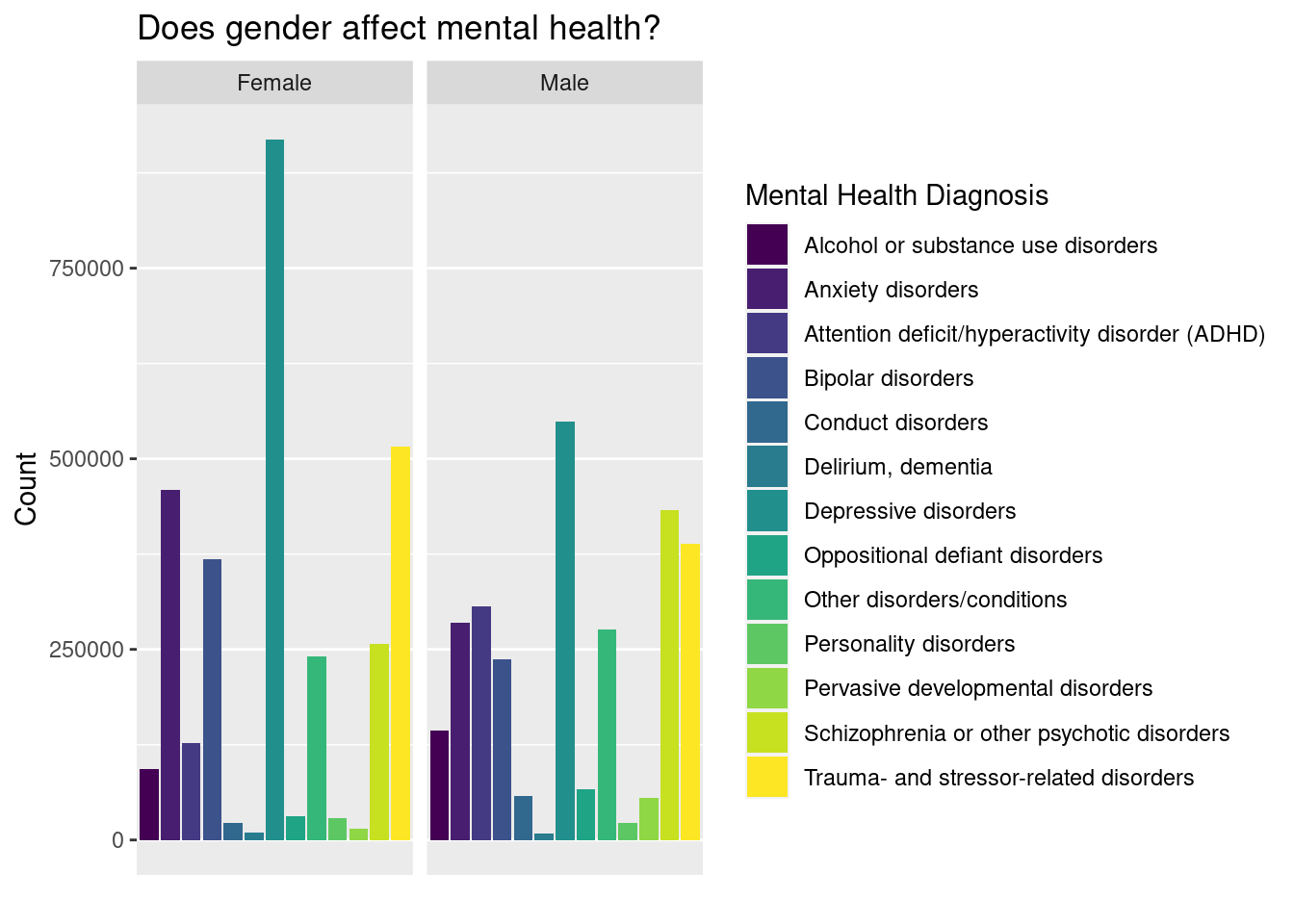
Gender - The gender counts/frequency records the clients most recent sex reported at the end of the reporting period. There is also a level for missing data.
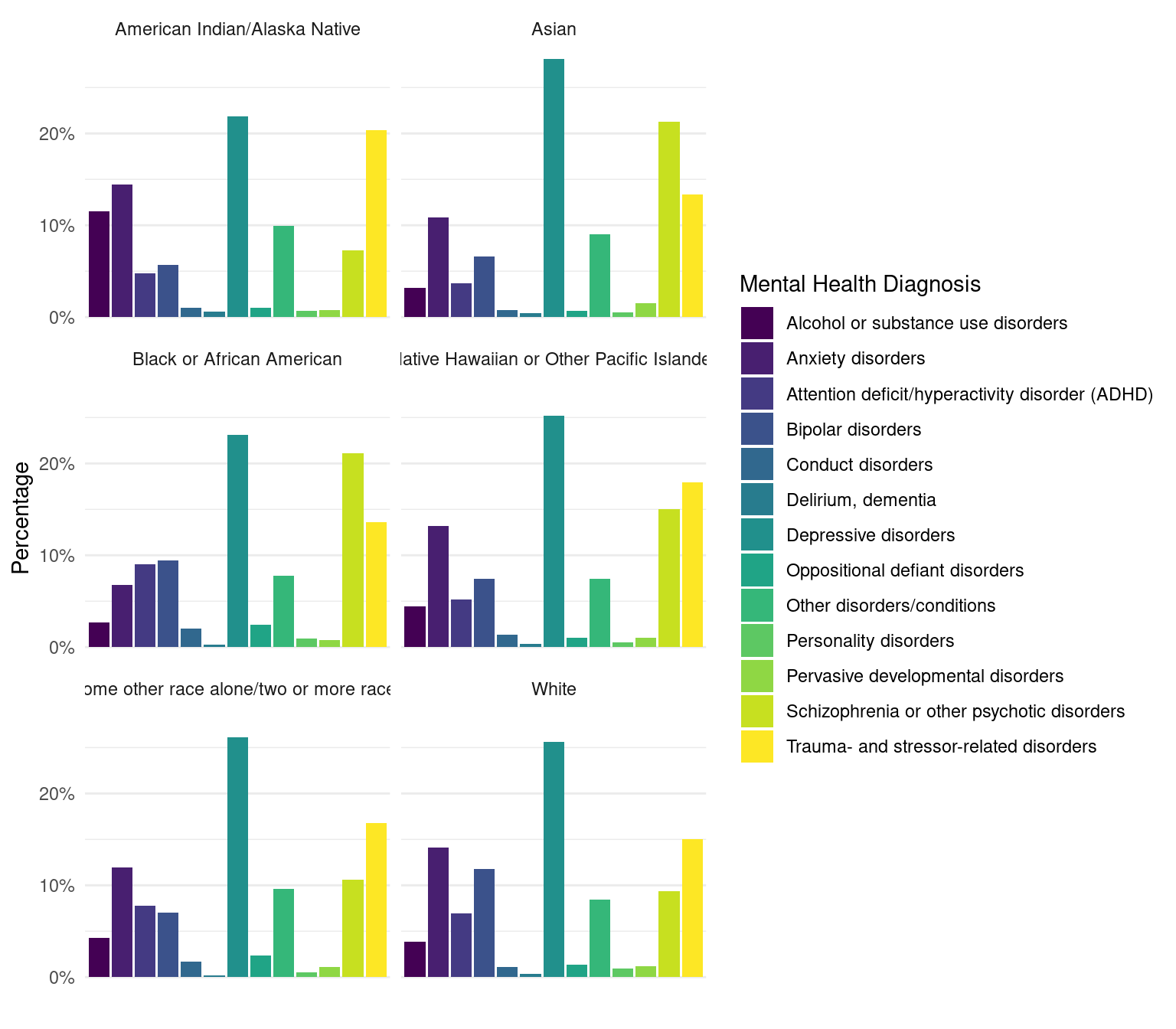
Race - Records frequency for races between patients. Levels include “Native American, Asian, Black, Native Hawaiian/Pacific Islander, White, Some other race/two or more races, and missing values. For each category there is a count table and percentage of the group. Minority Groups are any race besides white (white makes up 59.6% of the data).
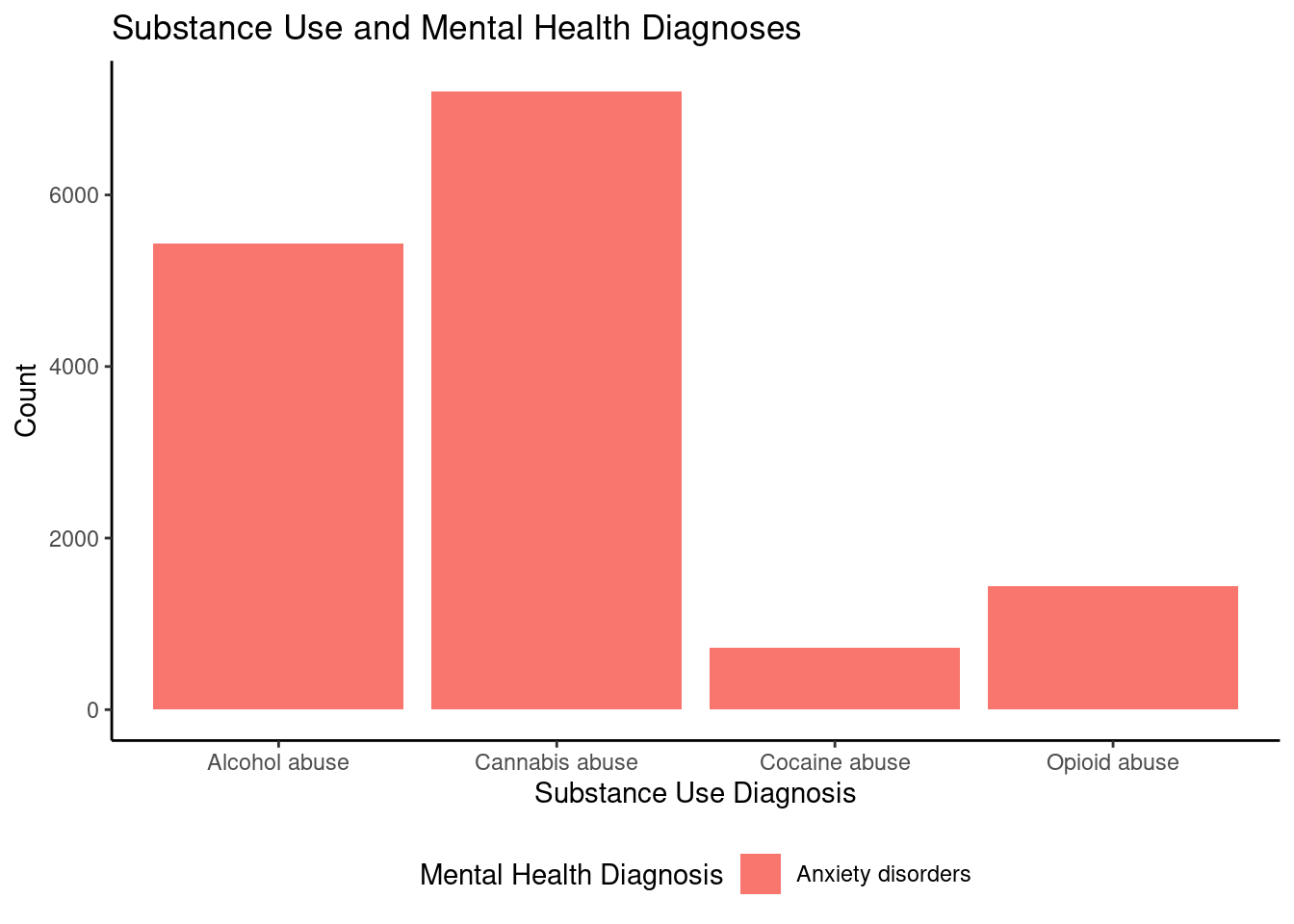
Substance - Records substance use with frequency and weighted percent. Counts recorded for alcohol
Data limitations
The dataset only contains information based solely on 2020 which may not be enough to truly show a relationship. Since we are only using one year it is impossible to see the way this data has changed over time. Another limitation of this dataset is that since this data was gotten through a survey it is quite possible that there maybe some form of misinformation amongst it.
Exploratory data analysis
Perform an (initial) exploratory data analysis.
# exploring gender data setgender_df <-read_csv("data/Final_Data/Clean_Data/GENDER_MH1_CLEAN.csv") |>filter(mental_health_diagnosis_one !="Missing/unknown/not collected/invalid/no or deferred diagnosis") |>group_by(sex)
Rows: 27 Columns: 3
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (2): sex, mental_health_diagnosis_one
dbl (1): sex_count
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Rows: 83 Columns: 3
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (2): race, mental_health_diagnosis_one
dbl (1): race_count
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Rows: 181 Columns: 3
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (2): substance_use_diagnosis, mental_health_diagnosis_one
dbl (1): sub_count
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
ggplot(bipolar_filtered, aes(x = substance_use_diagnosis, y = sub_count, fill = mental_health_diagnosis_one)) +geom_bar(stat ="identity", position ="dodge") +labs(title ="Substance Use and Mental Health Diagnoses",x ="Substance Use Diagnosis",y ="Count",fill ="Mental Health Diagnosis") +theme_classic() +theme(legend.position ="bottom")
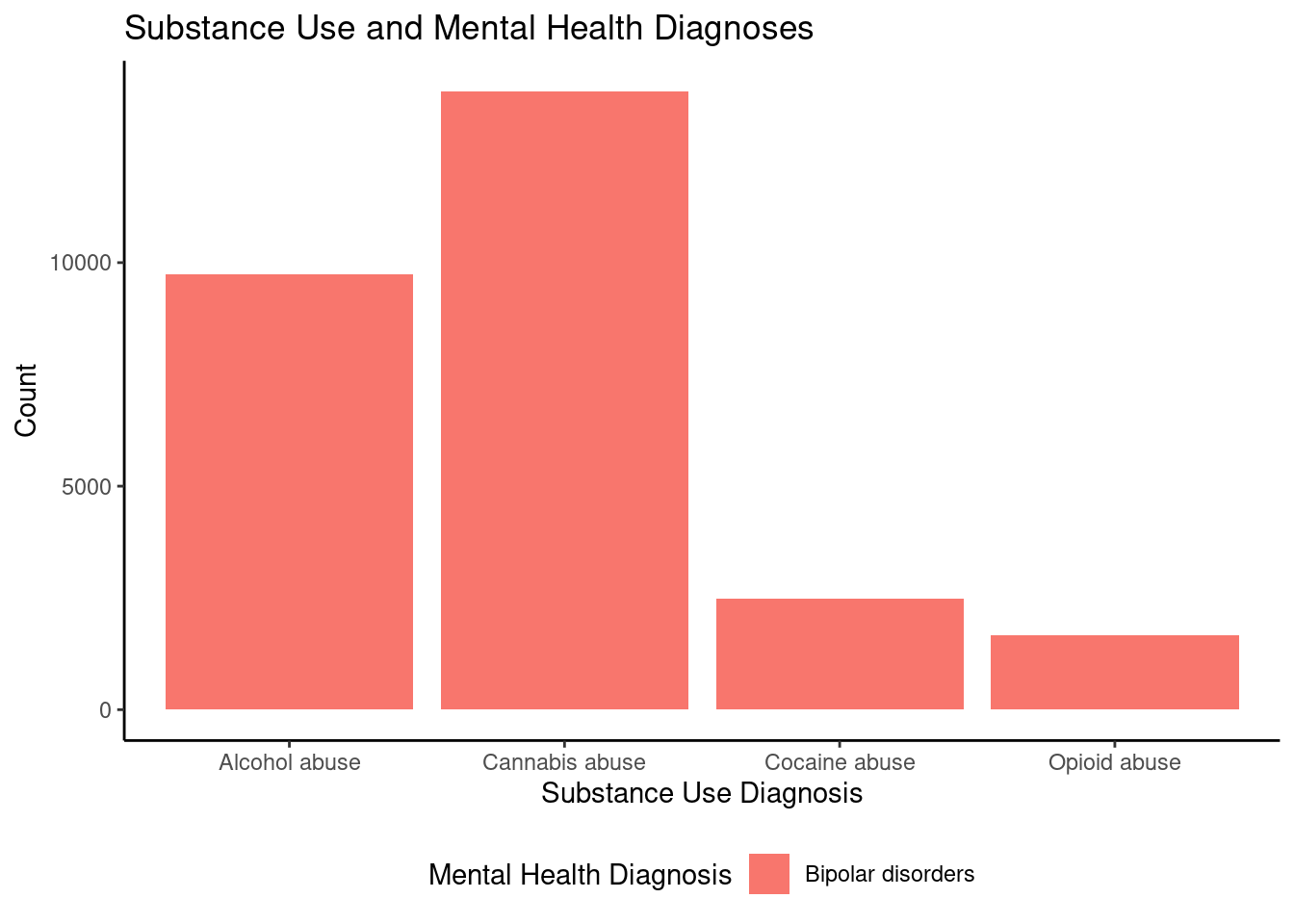
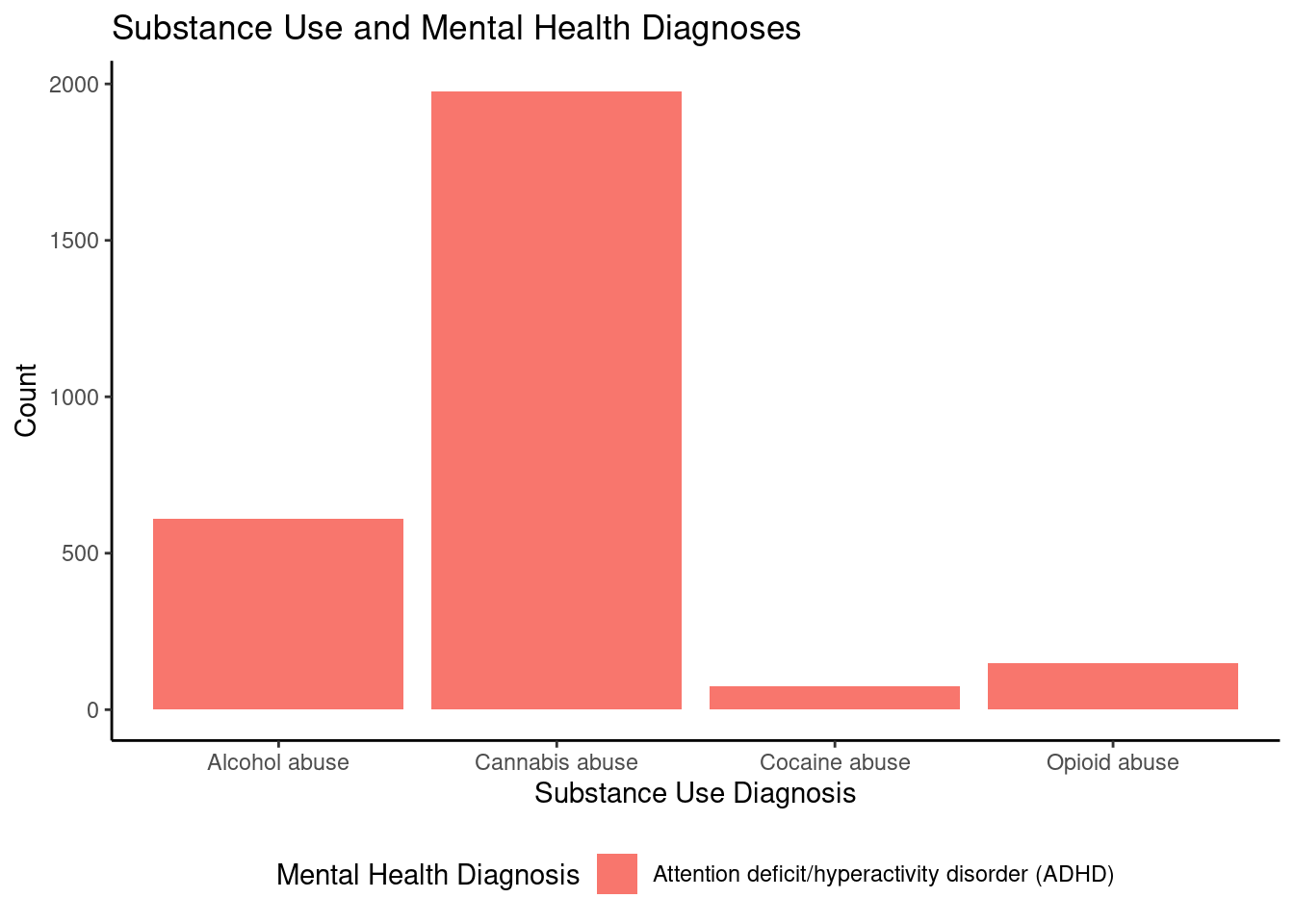
ggplot(adhd_filtered, aes(x = substance_use_diagnosis, y = sub_count, fill = mental_health_diagnosis_one)) +geom_bar(stat ="identity", position ="dodge") +labs(title ="Substance Use and Mental Health Diagnoses",x ="Substance Use Diagnosis",y ="Count",fill ="Mental Health Diagnosis") +theme_classic() +theme(legend.position ="bottom")
Questions for reviewers
What is the best way to join the separate data sets together? Should we join them together for ease of analysis? Is it okay that the data are in frequency tables? When downloading the data, we could only run a crosstab between two variables rather than accessing the full data frame.
We were thinking that there should be 8 columns - age, education, ethnicity, gender, substance use, veteran status, or state resided in - with each row an individual surveyed. Then there would be several million rows… Is this a feasible solution? We are also not sure how we would wrangle the data into this format from the current, separate data sets.
How do we account for confounding factors in our analysis of the influence on race on mental health diagnosis? In the proposal feedback, it was mentioned that socioeconomic status should be taken into consideration. However, this was information does not exist in our data set.