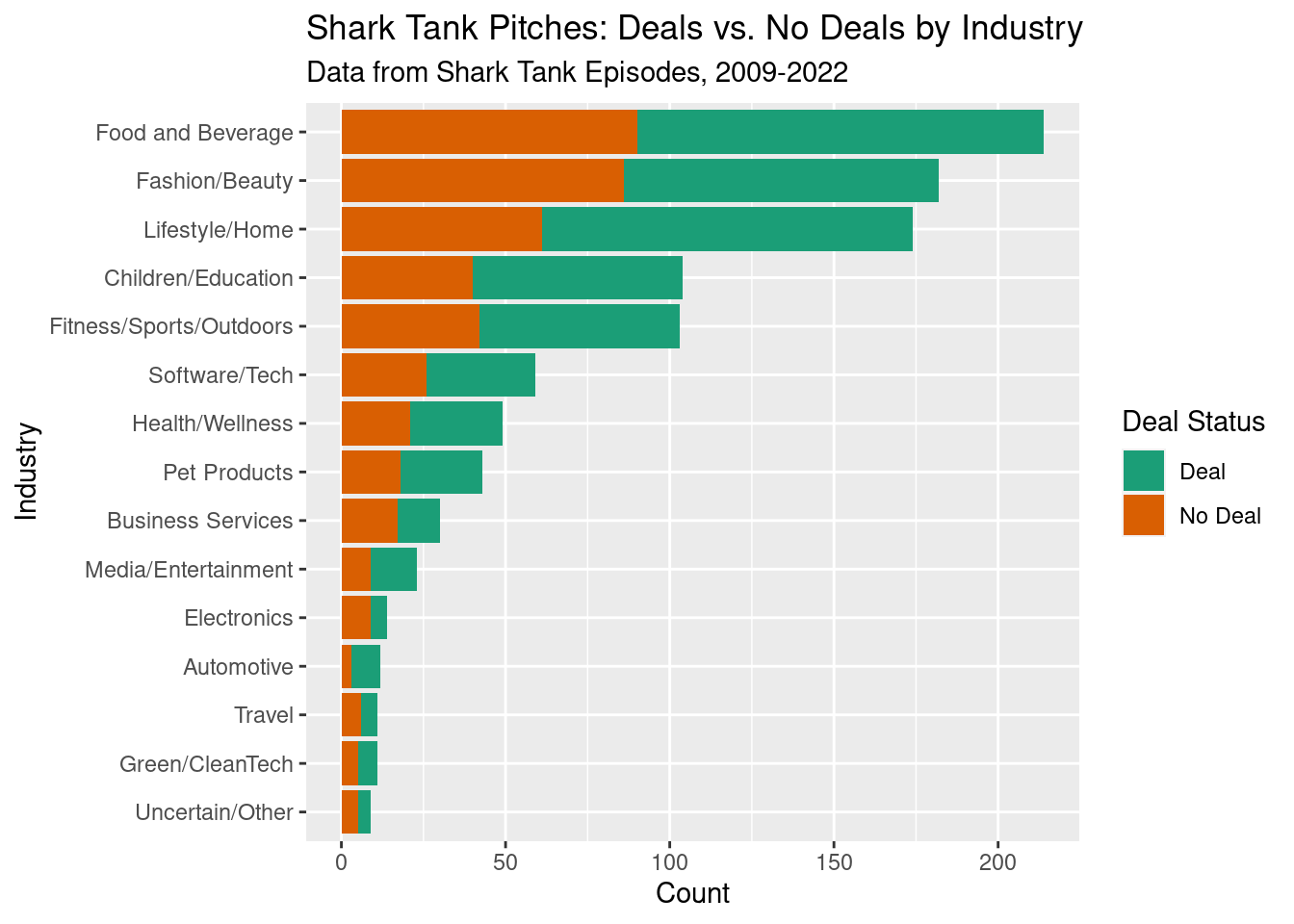
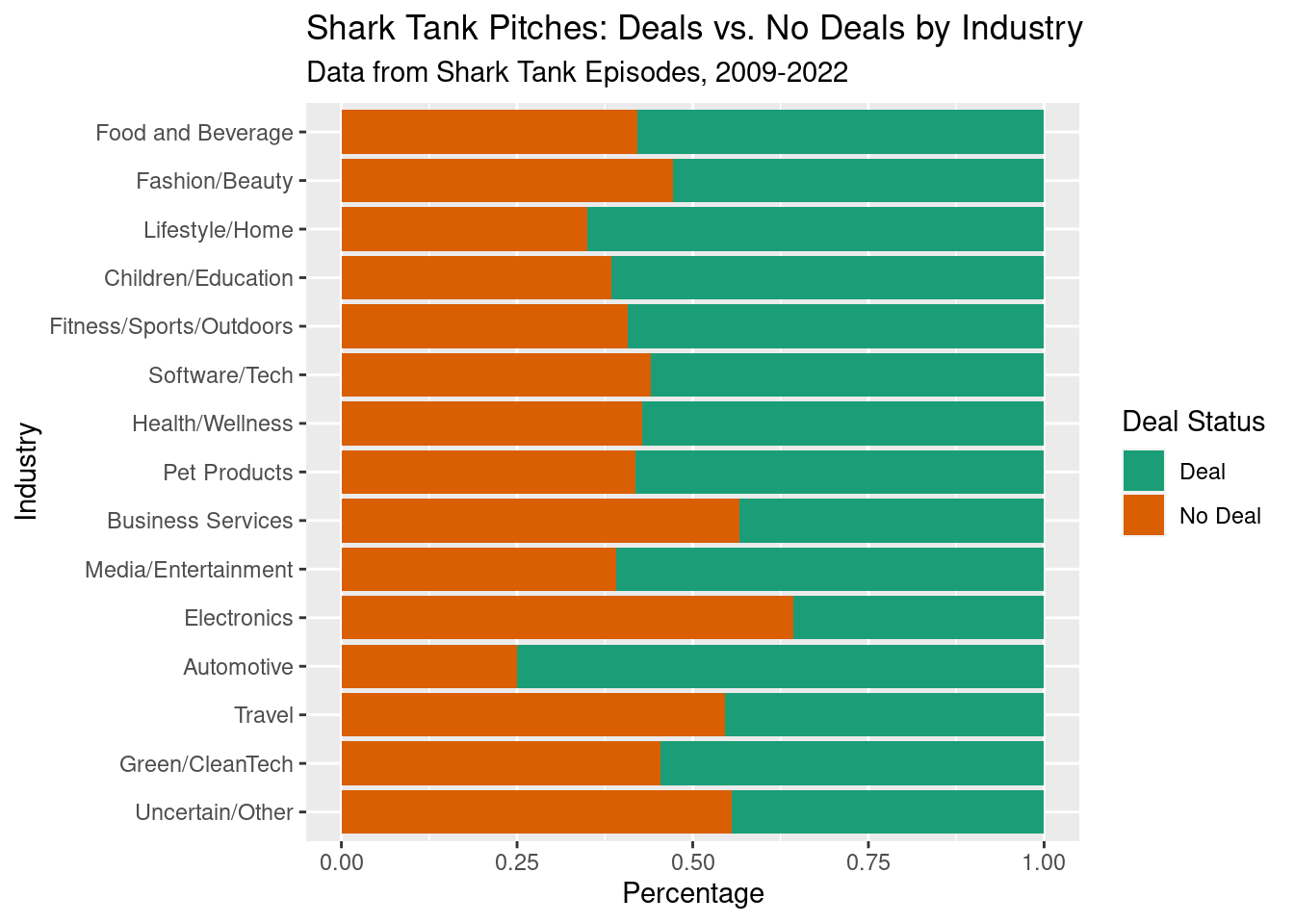
library(tidyverse)── Attaching packages ─────────────────────────────────────── tidyverse 1.3.2 ──
✔ ggplot2 3.4.0 ✔ purrr 1.0.0
✔ tibble 3.2.1 ✔ dplyr 1.1.2
✔ tidyr 1.2.1 ✔ stringr 1.5.0
✔ readr 2.1.3 ✔ forcats 0.5.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()library(skimr)
unwanted <- c('pitchers_average_age', 'company_website', 'business_description', 'notes')
shark_tank <- read_csv("data/shark_tank.csv") |>
janitor::clean_names() |>
select(!unwanted) |>
mutate(season_start = lubridate::dmy(season_start),
season_end = lubridate::dmy(season_end),
original_air_date = lubridate::dmy(original_air_date))Rows: 1038 Columns: 52
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (14): Season Start, Season End, Original Air Date, Startup Name, Industr...
dbl (38): Season Number, Episode Number, Pitch Number, Multiple Entrepreneur...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.Warning: Using an external vector in selections was deprecated in tidyselect 1.1.0.
ℹ Please use `all_of()` or `any_of()` instead.
# Was:
data %>% select(unwanted)
# Now:
data %>% select(all_of(unwanted))
See <https://tidyselect.r-lib.org/reference/faq-external-vector.html>.skim(shark_tank)| Name | shark_tank |
| Number of rows | 1038 |
| Number of columns | 48 |
| _______________________ | |
| Column type frequency: | |
| character | 7 |
| Date | 3 |
| numeric | 38 |
| ________________________ | |
| Group variables | None |
Variable type: character
| skim_variable | n_missing | complete_rate | min | max | empty | n_unique | whitespace |
|---|---|---|---|---|---|---|---|
| startup_name | 0 | 1.00 | 3 | 32 | 0 | 1036 | 0 |
| industry | 0 | 1.00 | 6 | 23 | 0 | 15 | 0 |
| pitchers_gender | 5 | 1.00 | 4 | 10 | 0 | 3 | 0 |
| pitchers_city | 540 | 0.48 | 3 | 18 | 0 | 250 | 0 |
| pitchers_state | 299 | 0.71 | 2 | 6 | 0 | 46 | 0 |
| entrepreneur_names | 557 | 0.46 | 8 | 60 | 0 | 479 | 0 |
| guest_name | 837 | 0.19 | 9 | 17 | 0 | 24 | 0 |
Variable type: Date
| skim_variable | n_missing | complete_rate | min | max | median | n_unique |
|---|---|---|---|---|---|---|
| season_start | 0 | 1.00 | 2009-08-09 | 2022-09-23 | 2015-09-25 | 14 |
| season_end | 7 | 0.99 | 2010-02-05 | 2022-05-20 | 2016-05-20 | 13 |
| original_air_date | 408 | 0.61 | 2009-08-09 | 2022-09-30 | 2014-01-13 | 154 |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| season_number | 0 | 1.00 | 6.76 | 3.11 | 1.00 | 4.00 | 7.00 | 9.00 | 1.400e+01 | ▃▇▅▇▁ |
| episode_number | 0 | 1.00 | 12.12 | 7.74 | 1.00 | 5.00 | 11.00 | 18.00 | 2.900e+01 | ▇▆▅▅▂ |
| pitch_number | 0 | 1.00 | 519.50 | 299.79 | 1.00 | 260.25 | 519.50 | 778.75 | 1.038e+03 | ▇▇▇▇▇ |
| multiple_entrepreneurs | 487 | 0.53 | 0.35 | 0.48 | 0.00 | 0.00 | 0.00 | 1.00 | 1.000e+00 | ▇▁▁▁▅ |
| us_viewership | 416 | 0.60 | 6.10 | 1.35 | 2.31 | 5.15 | 6.38 | 7.11 | 8.640e+00 | ▁▃▅▇▃ |
| original_ask_amount | 0 | 1.00 | 281798.65 | 379843.24 | 10000.00 | 100000.00 | 200000.00 | 300000.00 | 5.000e+06 | ▇▁▁▁▁ |
| original_offered_equity | 0 | 1.00 | 14.64 | 8.91 | 1.50 | 10.00 | 10.00 | 20.00 | 1.000e+02 | ▇▁▁▁▁ |
| valuation_requested | 0 | 1.00 | 3163290.63 | 4804725.88 | 40000.00 | 600000.00 | 1485294.00 | 3333333.00 | 4.500e+07 | ▇▁▁▁▁ |
| got_deal | 0 | 1.00 | 0.58 | 0.49 | 0.00 | 0.00 | 1.00 | 1.00 | 1.000e+00 | ▆▁▁▁▇ |
| total_deal_amount | 436 | 0.58 | 290921.37 | 378899.37 | 0.00 | 100000.00 | 200000.00 | 300000.00 | 5.000e+06 | ▇▁▁▁▁ |
| total_deal_equity | 436 | 0.58 | 25.51 | 16.18 | 0.00 | 15.00 | 25.00 | 33.00 | 1.000e+02 | ▇▇▂▁▁ |
| deal_valuation | 436 | 0.58 | 2042821.14 | 3718413.81 | 0.00 | 336206.75 | 800000.00 | 2000000.00 | 3.600e+07 | ▇▁▁▁▁ |
| number_of_sharks_in_deal | 436 | 0.58 | 1.32 | 0.63 | 1.00 | 1.00 | 1.00 | 2.00 | 5.000e+00 | ▇▂▁▁▁ |
| investment_amount_per_shark | 436 | 0.58 | 245115.72 | 350301.99 | 0.00 | 75000.00 | 150000.00 | 300000.00 | 5.000e+06 | ▇▁▁▁▁ |
| equity_per_shark | 436 | 0.58 | 21.55 | 15.17 | 0.00 | 10.00 | 20.00 | 25.00 | 1.000e+02 | ▇▅▁▁▁ |
| royalty_deal | 987 | 0.05 | 1.00 | 0.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.000e+00 | ▁▁▇▁▁ |
| loan | 1001 | 0.04 | 1.00 | 0.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.000e+00 | ▁▁▇▁▁ |
| barbara_corcoran_investment_amount | 940 | 0.09 | 143520.41 | 137398.90 | 12500.00 | 50000.00 | 100000.00 | 200000.00 | 1.000e+06 | ▇▂▁▁▁ |
| barbara_corcoran_investment_equity | 940 | 0.09 | 23.98 | 13.09 | 5.00 | 15.00 | 20.00 | 32.25 | 5.500e+01 | ▇▇▂▂▂ |
| mark_cuban_investment_amount | 857 | 0.17 | 245649.17 | 278613.24 | 12500.00 | 75000.00 | 150000.00 | 300000.00 | 2.000e+06 | ▇▁▁▁▁ |
| mark_cuban_investment_equity | 857 | 0.17 | 18.80 | 15.40 | 2.50 | 10.00 | 15.00 | 25.00 | 1.000e+02 | ▇▃▁▁▁ |
| lori_greiner_investment_amount | 882 | 0.15 | 205993.59 | 198022.87 | 17500.00 | 75000.00 | 150000.00 | 250000.00 | 1.000e+06 | ▇▂▁▁▁ |
| lori_greiner_investment_equity | 882 | 0.15 | 16.61 | 12.03 | 0.00 | 10.00 | 12.50 | 20.00 | 6.500e+01 | ▇▅▁▁▁ |
| robert_herjavec_investment_amount | 938 | 0.10 | 290973.33 | 581148.81 | 5000.00 | 86458.33 | 150000.00 | 300000.00 | 5.000e+06 | ▇▁▁▁▁ |
| robert_herjavec_investment_equity | 938 | 0.10 | 18.66 | 13.36 | 0.00 | 10.00 | 15.00 | 25.00 | 1.000e+02 | ▇▃▁▁▁ |
| daymond_john_investment_amount | 943 | 0.09 | 186805.26 | 319390.55 | 5000.00 | 50000.00 | 100000.00 | 240000.00 | 3.000e+06 | ▇▁▁▁▁ |
| daymond_john_investment_equity | 943 | 0.09 | 26.06 | 16.18 | 0.00 | 15.82 | 25.00 | 33.30 | 1.000e+02 | ▇▇▁▁▁ |
| kevin_o_leary_investment_amount | 942 | 0.09 | 236276.04 | 315926.33 | 20000.00 | 80000.00 | 150000.00 | 250000.00 | 2.500e+06 | ▇▁▁▁▁ |
| kevin_o_leary_investment_equity | 942 | 0.09 | 15.83 | 11.65 | 0.00 | 8.56 | 10.83 | 25.00 | 5.000e+01 | ▇▃▂▁▁ |
| guest_investment_amount | 969 | 0.07 | 216606.28 | 239754.19 | 0.00 | 75000.00 | 125000.00 | 250000.00 | 1.250e+06 | ▇▂▁▁▁ |
| guest_investment_equity | 969 | 0.07 | 16.71 | 15.52 | 0.00 | 10.00 | 11.25 | 20.00 | 1.000e+02 | ▇▂▁▁▁ |
| barbara_corcoran_present | 143 | 0.86 | 0.56 | 0.50 | 0.00 | 0.00 | 1.00 | 1.00 | 1.000e+00 | ▆▁▁▁▇ |
| mark_cuban_present | 142 | 0.86 | 0.90 | 0.30 | 0.00 | 1.00 | 1.00 | 1.00 | 1.000e+00 | ▁▁▁▁▇ |
| lori_greiner_present | 142 | 0.86 | 0.75 | 0.43 | 0.00 | 0.75 | 1.00 | 1.00 | 1.000e+00 | ▂▁▁▁▇ |
| robert_herjavec_present | 142 | 0.86 | 0.88 | 0.33 | 0.00 | 1.00 | 1.00 | 1.00 | 1.000e+00 | ▁▁▁▁▇ |
| daymond_john_present | 143 | 0.86 | 0.66 | 0.47 | 0.00 | 0.00 | 1.00 | 1.00 | 1.000e+00 | ▅▁▁▁▇ |
| kevin_o_leary_present | 143 | 0.86 | 0.96 | 0.21 | 0.00 | 1.00 | 1.00 | 1.00 | 1.000e+00 | ▁▁▁▁▇ |
| kevin_harrington_present | 143 | 0.86 | 0.95 | 0.23 | 0.00 | 1.00 | 1.00 | 1.00 | 1.000e+00 | ▁▁▁▁▇ |
glimpse(shark_tank)Rows: 1,038
Columns: 48
$ season_number <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,…
$ season_start <date> 2009-08-09, 2009-08-09, 2009-08-09…
$ season_end <date> 2010-02-05, 2010-02-05, 2010-02-05…
$ episode_number <dbl> 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 3, 3,…
$ pitch_number <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, …
$ original_air_date <date> 2009-08-09, 2009-08-09, 2009-08-09…
$ startup_name <chr> "AvaTheElephant", "Mr.Tod'sPieFacto…
$ industry <chr> "Health/Wellness", "Food and Bevera…
$ pitchers_gender <chr> "Female", "Male", "Male", "Male", "…
$ pitchers_city <chr> "Atlanta", "Somerset", "Cary", "Tam…
$ pitchers_state <chr> "GA", "NJ", "NC", "FL", "MN", "CA",…
$ entrepreneur_names <chr> "Tiffany Krumins", "Tod Wilson", "K…
$ multiple_entrepreneurs <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
$ us_viewership <dbl> 4.15, 4.15, 4.15, 4.15, 4.15, 5.59,…
$ original_ask_amount <dbl> 50000, 460000, 1200000, 250000, 100…
$ original_offered_equity <dbl> 15, 10, 10, 25, 15, 15, 10, 10, 20,…
$ valuation_requested <dbl> 333333, 4600000, 12000000, 1000000,…
$ got_deal <dbl> 1, 1, 0, 0, 0, 1, 1, 0, 0, 0, 1, 1,…
$ total_deal_amount <dbl> 50000, 460000, NA, NA, NA, 500000, …
$ total_deal_equity <dbl> 55, 50, NA, NA, NA, 50, 100, NA, NA…
$ deal_valuation <dbl> 90909, 920000, NA, NA, NA, 1000000,…
$ number_of_sharks_in_deal <dbl> 1, 2, NA, NA, NA, 2, 5, NA, NA, NA,…
$ investment_amount_per_shark <dbl> 50000, 230000, NA, NA, NA, 250000, …
$ equity_per_shark <dbl> 55.0, 25.0, NA, NA, NA, 25.0, 20.0,…
$ royalty_deal <dbl> NA, NA, NA, NA, NA, NA, 1, NA, NA, …
$ loan <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ barbara_corcoran_investment_amount <dbl> 50000, 230000, NA, NA, NA, NA, 5000…
$ barbara_corcoran_investment_equity <dbl> 55, 25, NA, NA, NA, NA, 20, NA, NA,…
$ mark_cuban_investment_amount <dbl> NA, NA, NA, NA, NA, NA, 50000, NA, …
$ mark_cuban_investment_equity <dbl> NA, NA, NA, NA, NA, NA, 20, NA, NA,…
$ lori_greiner_investment_amount <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ lori_greiner_investment_equity <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ robert_herjavec_investment_amount <dbl> NA, NA, NA, NA, NA, 250000, 50000, …
$ robert_herjavec_investment_equity <dbl> NA, NA, NA, NA, NA, 25.0, 20.0, NA,…
$ daymond_john_investment_amount <dbl> NA, 230000, NA, NA, NA, NA, 50000, …
$ daymond_john_investment_equity <dbl> NA, 25, NA, NA, NA, NA, 20, NA, NA,…
$ kevin_o_leary_investment_amount <dbl> NA, NA, NA, NA, NA, 250000, 50000, …
$ kevin_o_leary_investment_equity <dbl> NA, NA, NA, NA, NA, 25.0, 20.0, NA,…
$ guest_investment_amount <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ guest_investment_equity <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ barbara_corcoran_present <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,…
$ mark_cuban_present <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
$ lori_greiner_present <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
$ robert_herjavec_present <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,…
$ daymond_john_present <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,…
$ kevin_o_leary_present <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,…
$ kevin_harrington_present <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,…
$ guest_name <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA,…