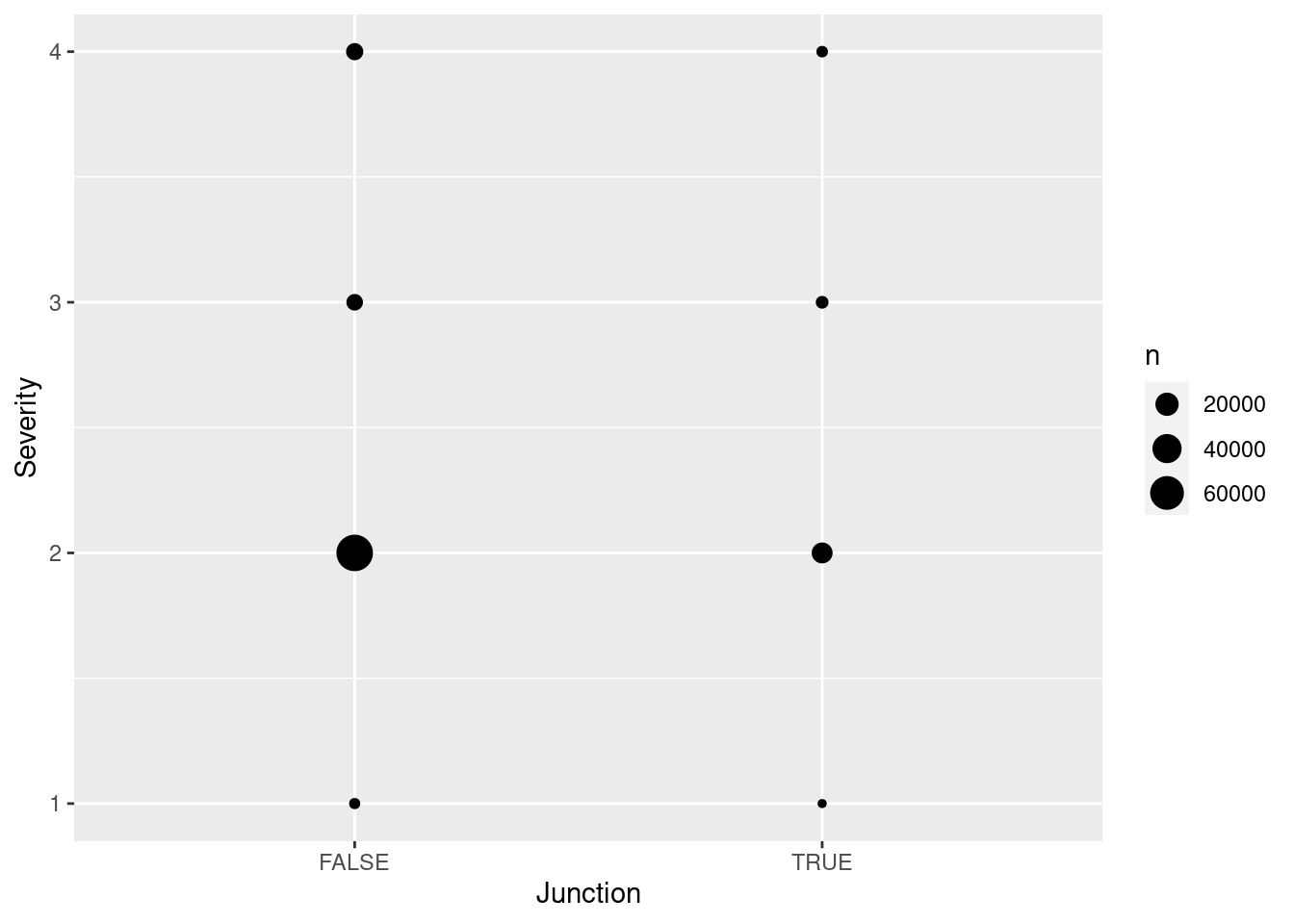
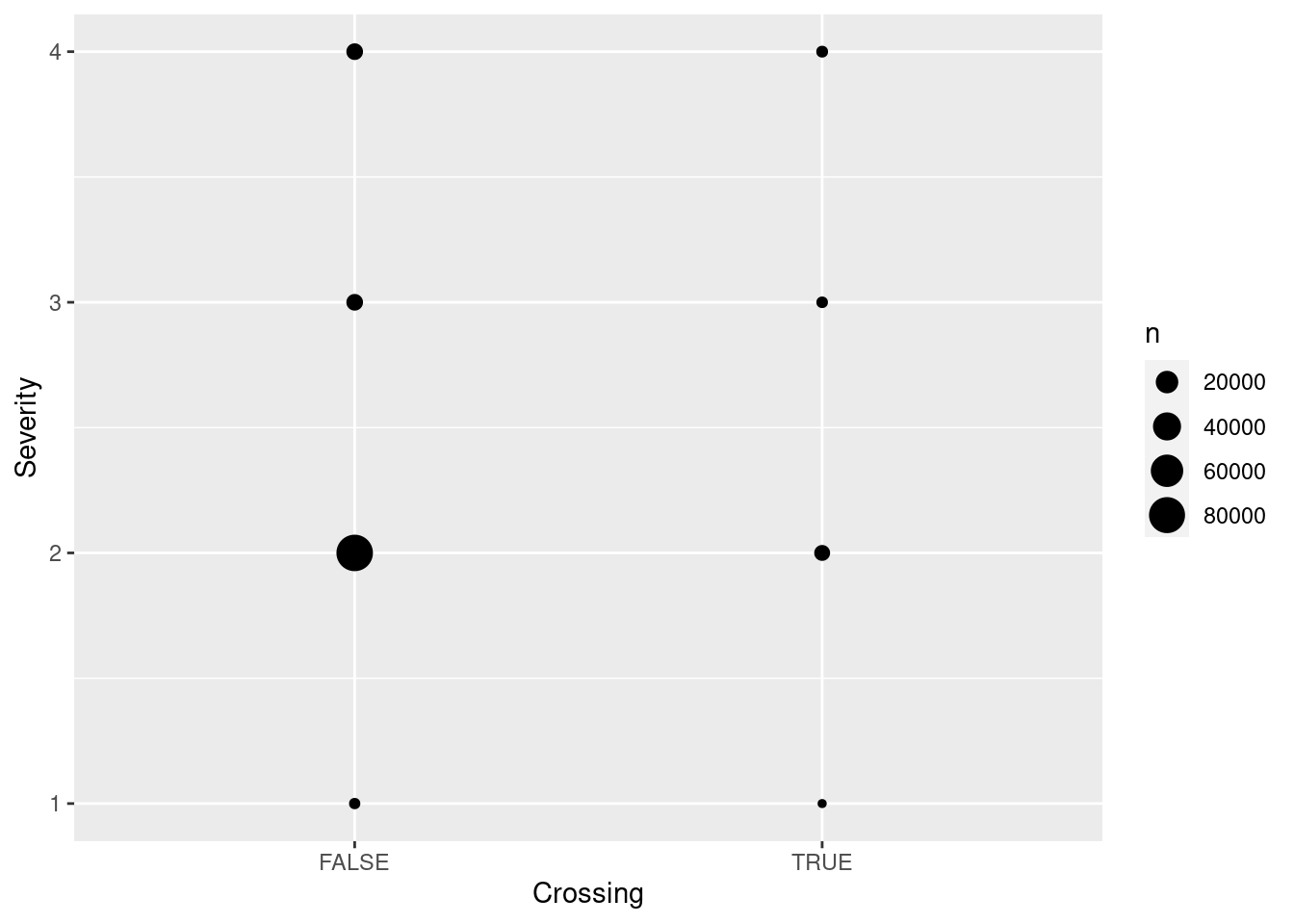
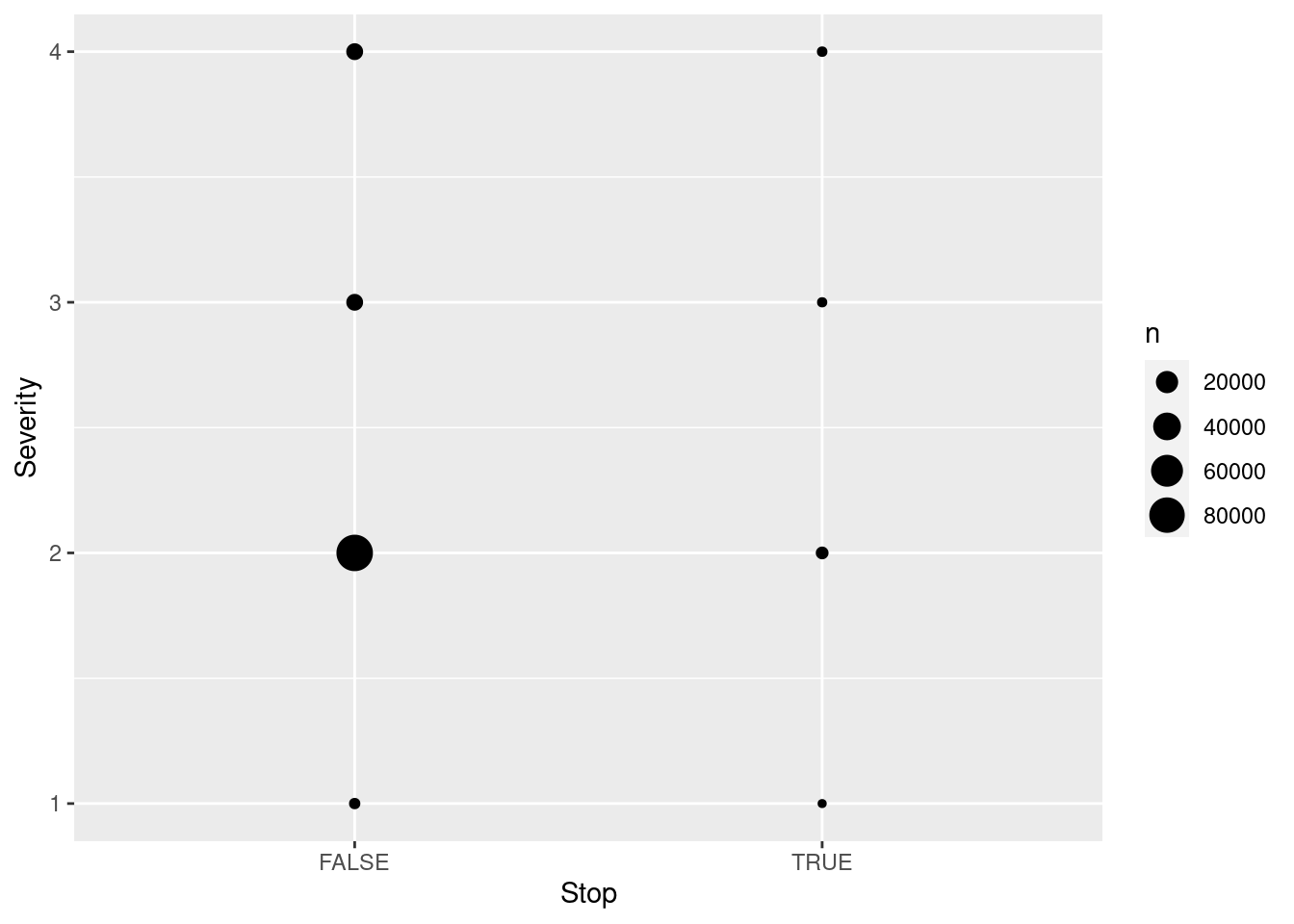
What are the major factors affecting accident severity?
How does time of day affect accident severity?
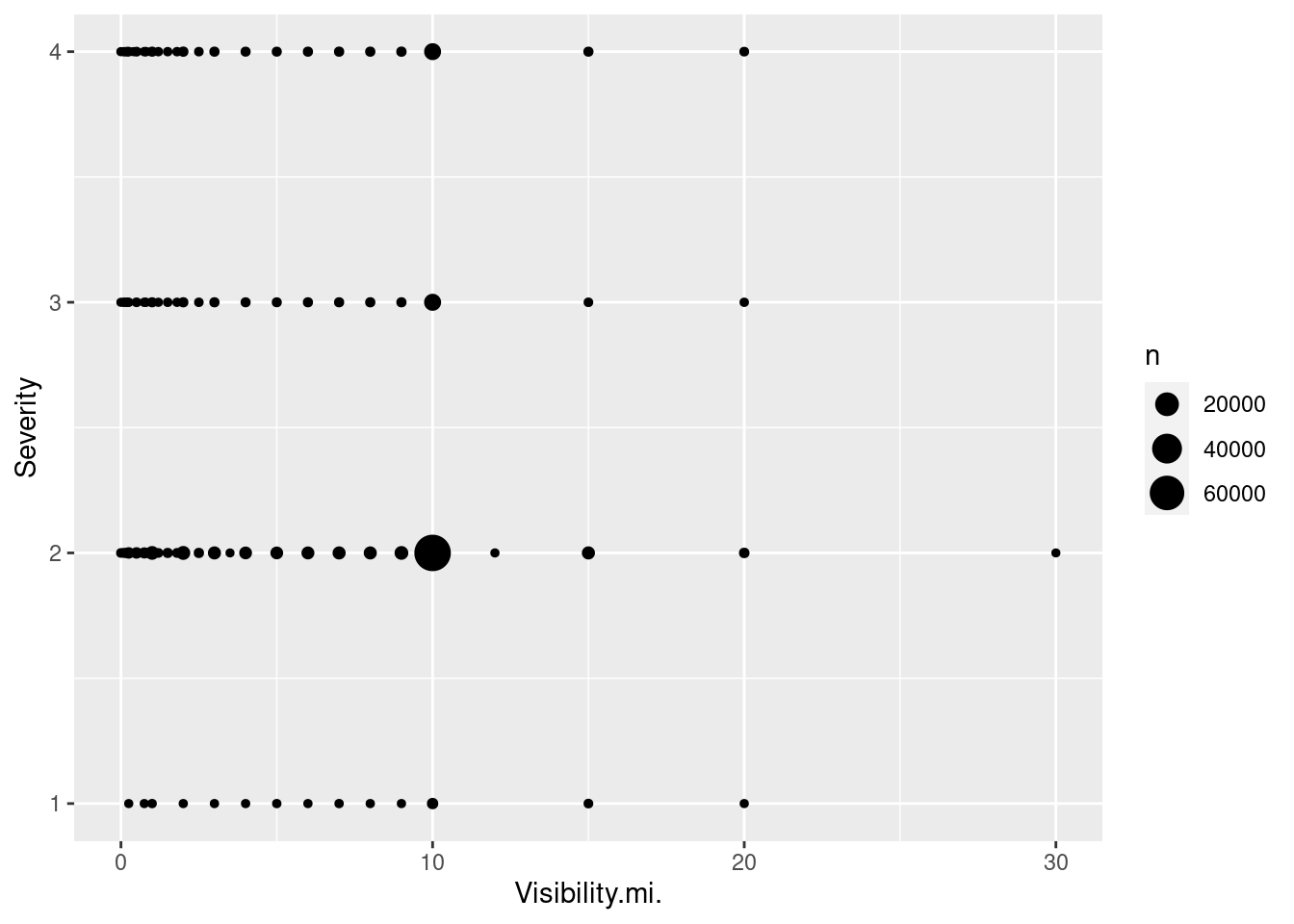
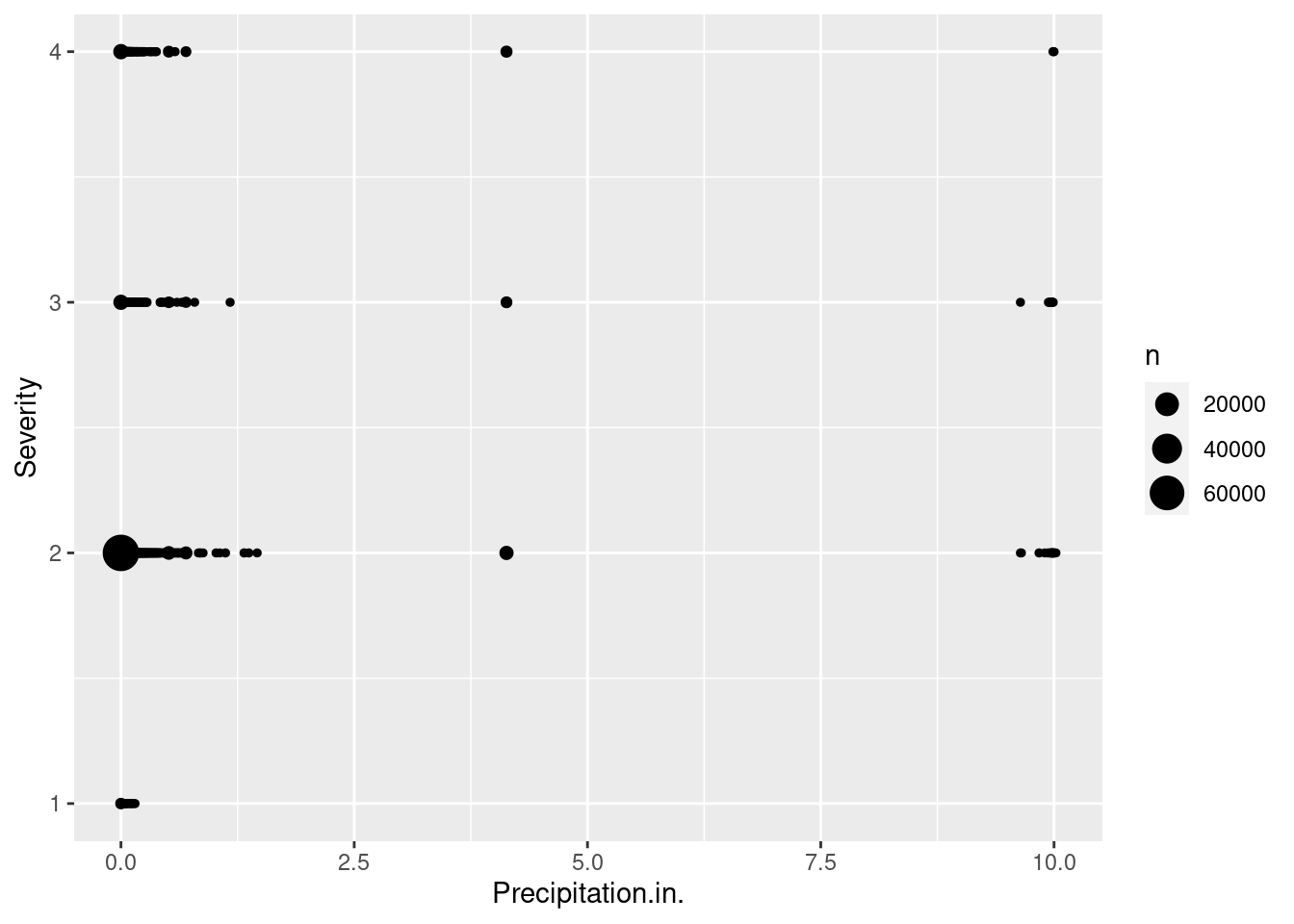
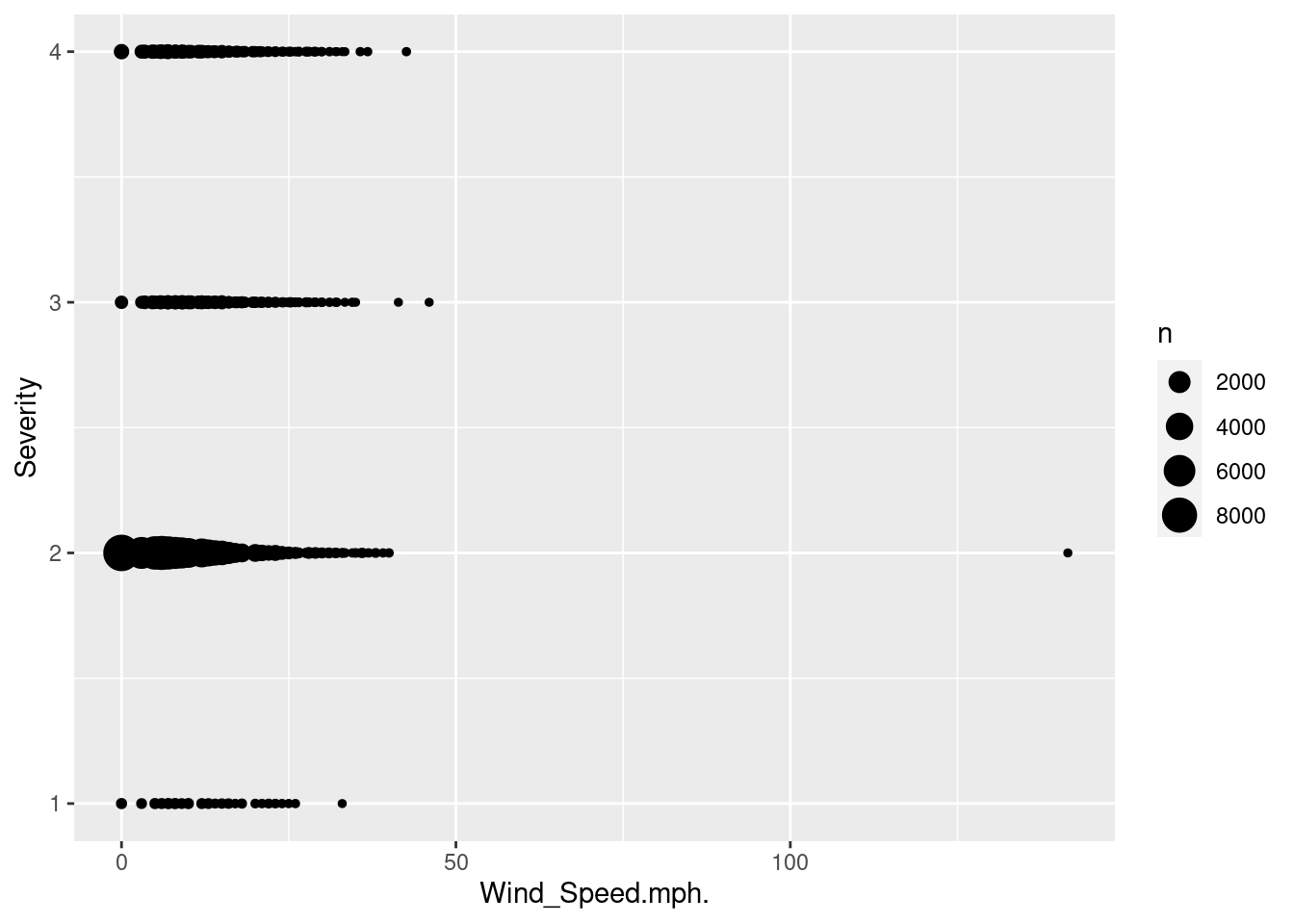
How does weather affect the probability of an accident being deemed less/more severe?
Data collection and cleaning
This data set was collected using multiple APIs that provide streaming traffic incident (or event) data. These APIs broadcast traffic data captured by a variety of entities, such as the US and state departments of transportation, law enforcement agencies, traffic cameras, and traffic sensors within the road-networks.
The full data set was collected for analysis in the paper Moosavi, Sobhan, Mohammad Hossein Samavatian, Srinivasan Parthasarathy, and Rajiv Ramnath. “A Countrywide Traffic Accident Dataset.”, 2019 and is available in full from Kaggle. Moosavi’s team collected traffic accident data from 2016-2021 for 49 US States.
Cleaning of the data set for this analysis involved narrowing the scope of the data set to just accidents occurring in the state of New York in the 5 year time frame. This analysis also choose to limit the focus of “Accident Infrastructure” variables to the four most common types as many indicators were present in <<1% of the observations.
Additional extraneous accident details such as variables surrounding the exact accident location and weather variables irrelevant to our analysis were excluded in the data cleaning. Full data cleaning scripts and further justification for the exclusion of certain variables are included in the data cleaning appendix.
Data description
The data set for this analysis contains 107,124 rows (observations), with each row corresponding to one recorded traffic accident in the State of New York between 2016 and 2021. Each traffic accident has 16 associated variables with it:
Severity: severity of the accident, with 1 = lowest impact to traffic and 4 = greatest impact to traffic. (categorical)
Start_Time: date and time when the accident occurred (quantitative)
End_Time: date and time when the local roadway was clear of the accident (quantitative)
Distance.mi: length of road affected by accident, in miles (quantitative)
Location Data:
City (categorical)
County (categorical)
Weather Data (meteorological data obtained from the closest airport to the accident site):
Weather_Condition (categorical)
Precipitation (in millimeters) (quantitative)
Temperature (in degrees F) (quantitative)
Wind Speed (mph) (quantitative)
Visibility.mi (in miles) (quantitative)
Sunrise_Sunset: Shows the period of day (i.e. day or night) based on sunrise/sunset (qualitative)
Accident Infrastructure:
Crossing: presence of a crossing in nearby area (logical)
Junction: presence of a junction in nearby area (logical)
Stop: presence of a stop in nearby area (logical)
Traffic_Signal: presence of a traffic signal in nearby area (logical)
Per the authors, this data set was created “for numerous applications such as real-time car accident prediction, studying car accidents hotspot locations, casualty analysis and extracting cause and effect rules to predict car accidents, and studying the impact of precipitation or other environmental stimuli on accident occurrence.” In this analysis, we focused on car-accident prediction and the impact of daytime/nighttime and other weather data on accident occurrence.
The data set collection was supported by a grant from the Ohio Supercomputer Center (PAS0536).
Processes that might have influenced what data was observed and recorded and what was not in the original data set include the fact that data was recorded from state and local level sources, which may have varying standards and practices as to how their data for each accident is recorded, classified, and imputed. The authors define their data collection process as “collected streaming traffic data using two real-time data providers, namely”MapQuest Traffic” and “Microsoft Bing Map Traffic”, whose APIs broadcast traffic events (accident, congestion, etc.) captured by a variety of entities - the US and state departments of transportation, law enforcement agencies, traffic cameras, and traffic sensors within the road-networks.” Since our analysis limits the original data set down to one state (NY), irregularities between observations are dampened, however there may still exist differences between upstate and downstate recording of accidents, or minor accidents in rural portions of the state being underreported.
Additional pre-processing from the data set authors included accessing the weather underground API to obtain weather information for each accident based on conditions at the nearest airport. Using the geo-location data, the authors used the Open Streetmaps API and formulas to verify if the accident was associated with a particular POI (point of interest, or as we use here, “accident infrastructure” ) such as a stop sign, traffic signal, etc. Thresholds were defined by the authors for each POI’s relevance to the accident to determine the logical value for each accident infrastructure and to maintain consistency for each observation. Details on the exact methods of the thresholds are described in the aforementioned paper.
Data limitations
We have identified two main limitations with our data:
Outcome variable of severity: There are several issues with our outcome variables regarding severity. Firstly, severity is currently measured on a scale of 1 to 4. However, in order to use it in our model, we will have to classify accidents as more or less severe by grouping 1 and 2 as 0, and 3 and 4 as 1 to perform logistic regression. This has the potential to impact the precision of our model. Furthermore, severity is measured in terms of its impact on traffic, specifically the time it takes for the accident to be cleared. While this measure is often significantly correlated with actual severity, it may not capture more important outcomes such as injuries, loss of life, or monetary damage to vehicles.
Use of NY State: When using data from NY state alone to determine the factors that influence accident severity, several potential issues may arise. Firstly, the results obtained may not be generalizable to other regions or countries, as the factors that affect accident severity may differ. Secondly, the sample size may be small for an experiment like this, resulting in low statistical power and difficulties in drawing accurate conclusions. Thirdly, there may be bias in the analysis if the data used is not representative of all accidents in NY state.
New names:
Rows: 102961 Columns: 17
── Column specification
──────────────────────────────────────────────────────── Delimiter: "," chr
(4): City, County, Weather_Condition, Sunrise_Sunset dbl (7): ...1, Severity,
Distance.mi., Temperature.F., Visibility.mi., Wind... lgl (4): Crossing,
Junction, Stop, Traffic_Signal dttm (2): Start_Time, End_Time
ℹ Use `spec()` to retrieve the full column specification for this data. ℹ
Specify the column types or set `show_col_types = FALSE` to quiet this message.
• `` -> `...1`