library(tidyverse)
library(skimr)
library(jsonlite)
library(dplyr)
library(scales)
library(tidymodels)
library(lubridate)Analyzing Airbnb data
Exploratory data analysis
# Load airbnb listings data (03/06/2023)
airbnb_data <- read_csv("data/airbnb_data/03_06_2023_listings.csv")
# Preview some rows
head(airbnb_data)# A tibble: 6 × 75
id listing_url scrape_id last_scraped source name description
<dbl> <chr> <dbl> <date> <chr> <chr> <chr>
1 8.02e17 https://www.airbnb.co… 2.02e13 2023-03-06 city … A ho… The whole …
2 7.66e17 https://www.airbnb.co… 2.02e13 2023-03-06 city … Broo… Take a bre…
3 6.36e17 https://www.airbnb.co… 2.02e13 2023-03-06 city … Vill… Close to b…
4 7.68e17 https://www.airbnb.co… 2.02e13 2023-03-06 city … 1-Be… Private ro…
5 4.92e 7 https://www.airbnb.co… 2.02e13 2023-03-06 city … Get … Welcome to…
6 5.21e 7 https://www.airbnb.co… 2.02e13 2023-03-06 city … Room… 房间内带有…
# ℹ 68 more variables: neighborhood_overview <chr>, picture_url <chr>,
# host_id <dbl>, host_url <chr>, host_name <chr>, host_since <date>,
# host_location <chr>, host_about <chr>, host_response_time <chr>,
# host_response_rate <chr>, host_acceptance_rate <chr>,
# host_is_superhost <lgl>, host_thumbnail_url <chr>, host_picture_url <chr>,
# host_neighbourhood <chr>, host_listings_count <dbl>,
# host_total_listings_count <dbl>, host_verifications <chr>, …# Skim through data
skim(airbnb_data)| Name | airbnb_data |
| Number of rows | 42931 |
| Number of columns | 75 |
| _______________________ | |
| Column type frequency: | |
| character | 26 |
| Date | 5 |
| logical | 7 |
| numeric | 37 |
| ________________________ | |
| Group variables | None |
Variable type: character
| skim_variable | n_missing | complete_rate | min | max | empty | n_unique | whitespace |
|---|---|---|---|---|---|---|---|
| listing_url | 0 | 1.00 | 33 | 47 | 0 | 42931 | 0 |
| source | 0 | 1.00 | 11 | 15 | 0 | 2 | 0 |
| name | 10 | 1.00 | 1 | 248 | 0 | 41409 | 0 |
| description | 752 | 0.98 | 1 | 1000 | 0 | 38022 | 0 |
| neighborhood_overview | 18060 | 0.58 | 1 | 1000 | 0 | 19579 | 0 |
| picture_url | 0 | 1.00 | 60 | 126 | 0 | 41814 | 0 |
| host_url | 0 | 1.00 | 38 | 43 | 0 | 27455 | 0 |
| host_name | 5 | 1.00 | 1 | 35 | 0 | 9831 | 0 |
| host_location | 9086 | 0.79 | 5 | 40 | 0 | 1125 | 0 |
| host_about | 19677 | 0.54 | 1 | 7309 | 0 | 14251 | 26 |
| host_response_time | 5 | 1.00 | 3 | 18 | 0 | 5 | 0 |
| host_response_rate | 5 | 1.00 | 2 | 4 | 0 | 74 | 0 |
| host_acceptance_rate | 5 | 1.00 | 2 | 4 | 0 | 99 | 0 |
| host_thumbnail_url | 5 | 1.00 | 55 | 106 | 0 | 26859 | 0 |
| host_picture_url | 5 | 1.00 | 57 | 109 | 0 | 26859 | 0 |
| host_neighbourhood | 8650 | 0.80 | 4 | 50 | 0 | 550 | 0 |
| host_verifications | 0 | 1.00 | 2 | 32 | 0 | 8 | 0 |
| neighbourhood | 18060 | 0.58 | 13 | 55 | 0 | 187 | 0 |
| neighbourhood_cleansed | 0 | 1.00 | 4 | 25 | 0 | 223 | 0 |
| neighbourhood_group_cleansed | 0 | 1.00 | 5 | 13 | 0 | 5 | 0 |
| property_type | 0 | 1.00 | 4 | 34 | 0 | 80 | 0 |
| room_type | 0 | 1.00 | 10 | 15 | 0 | 4 | 0 |
| bathrooms_text | 75 | 1.00 | 6 | 17 | 0 | 30 | 0 |
| amenities | 0 | 1.00 | 2 | 2212 | 0 | 36300 | 0 |
| price | 0 | 1.00 | 5 | 10 | 0 | 1089 | 0 |
| license | 42930 | 0.00 | 8 | 8 | 0 | 1 | 0 |
Variable type: Date
| skim_variable | n_missing | complete_rate | min | max | median | n_unique |
|---|---|---|---|---|---|---|
| last_scraped | 0 | 1.00 | 2023-03-06 | 2023-03-07 | 2023-03-06 | 2 |
| host_since | 5 | 1.00 | 2008-08-11 | 2023-03-04 | 2016-05-29 | 4747 |
| calendar_last_scraped | 0 | 1.00 | 2023-03-06 | 2023-03-07 | 2023-03-06 | 2 |
| first_review | 10304 | 0.76 | 2009-04-13 | 2023-03-06 | 2020-02-11 | 3843 |
| last_review | 10304 | 0.76 | 2011-05-12 | 2023-03-06 | 2022-11-23 | 2795 |
Variable type: logical
| skim_variable | n_missing | complete_rate | mean | count |
|---|---|---|---|---|
| host_is_superhost | 25 | 1 | 0.22 | FAL: 33487, TRU: 9419 |
| host_has_profile_pic | 5 | 1 | 0.98 | TRU: 42131, FAL: 795 |
| host_identity_verified | 5 | 1 | 0.85 | TRU: 36675, FAL: 6251 |
| bathrooms | 42931 | 0 | NaN | : |
| calendar_updated | 42931 | 0 | NaN | : |
| has_availability | 0 | 1 | 0.85 | TRU: 36660, FAL: 6271 |
| instant_bookable | 0 | 1 | 0.21 | FAL: 33908, TRU: 9023 |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| id | 0 | 1.00 | 2.222772e+17 | 3.344213e+17 | 2.595000e+03 | 1.940474e+07 | 4.337482e+07 | 6.305016e+17 | 8.404660e+17 | ▇▁▁▁▂ |
| scrape_id | 0 | 1.00 | 2.023031e+13 | 0.000000e+00 | 2.023031e+13 | 2.023031e+13 | 2.023031e+13 | 2.023031e+13 | 2.023031e+13 | ▁▁▇▁▁ |
| host_id | 0 | 1.00 | 1.516012e+08 | 1.621301e+08 | 1.678000e+03 | 1.608533e+07 | 7.433812e+07 | 2.680692e+08 | 5.038729e+08 | ▇▂▂▂▂ |
| host_listings_count | 5 | 1.00 | 1.077900e+02 | 5.816300e+02 | 1.000000e+00 | 1.000000e+00 | 2.000000e+00 | 5.000000e+00 | 4.774000e+03 | ▇▁▁▁▁ |
| host_total_listings_count | 5 | 1.00 | 1.558600e+02 | 7.997100e+02 | 1.000000e+00 | 1.000000e+00 | 3.000000e+00 | 7.000000e+00 | 8.298000e+03 | ▇▁▁▁▁ |
| latitude | 0 | 1.00 | 4.073000e+01 | 6.000000e-02 | 4.050000e+01 | 4.069000e+01 | 4.072000e+01 | 4.076000e+01 | 4.091000e+01 | ▁▂▇▅▁ |
| longitude | 0 | 1.00 | -7.394000e+01 | 6.000000e-02 | -7.425000e+01 | -7.398000e+01 | -7.395000e+01 | -7.392000e+01 | -7.371000e+01 | ▁▁▇▂▁ |
| accommodates | 0 | 1.00 | 2.970000e+00 | 2.120000e+00 | 0.000000e+00 | 2.000000e+00 | 2.000000e+00 | 4.000000e+00 | 1.600000e+01 | ▇▃▁▁▁ |
| bedrooms | 3874 | 0.91 | 1.400000e+00 | 7.900000e-01 | 1.000000e+00 | 1.000000e+00 | 1.000000e+00 | 2.000000e+00 | 1.600000e+01 | ▇▁▁▁▁ |
| beds | 929 | 0.98 | 1.660000e+00 | 1.170000e+00 | 1.000000e+00 | 1.000000e+00 | 1.000000e+00 | 2.000000e+00 | 4.200000e+01 | ▇▁▁▁▁ |
| minimum_nights | 0 | 1.00 | 1.811000e+01 | 2.746000e+01 | 1.000000e+00 | 2.000000e+00 | 7.000000e+00 | 3.000000e+01 | 1.250000e+03 | ▇▁▁▁▁ |
| maximum_nights | 0 | 1.00 | 5.152210e+04 | 1.036530e+07 | 1.000000e+00 | 6.000000e+01 | 3.650000e+02 | 1.125000e+03 | 2.147484e+09 | ▇▁▁▁▁ |
| minimum_minimum_nights | 14 | 1.00 | 1.797000e+01 | 2.980000e+01 | 1.000000e+00 | 2.000000e+00 | 7.000000e+00 | 3.000000e+01 | 1.250000e+03 | ▇▁▁▁▁ |
| maximum_minimum_nights | 14 | 1.00 | 2.313000e+01 | 4.783000e+01 | 1.000000e+00 | 2.000000e+00 | 1.000000e+01 | 3.000000e+01 | 1.250000e+03 | ▇▁▁▁▁ |
| minimum_maximum_nights | 14 | 1.00 | 1.252610e+06 | 5.181612e+07 | 1.000000e+00 | 3.600000e+02 | 1.125000e+03 | 1.125000e+03 | 2.147484e+09 | ▇▁▁▁▁ |
| maximum_maximum_nights | 14 | 1.00 | 2.503582e+06 | 7.325757e+07 | 1.000000e+00 | 3.650000e+02 | 1.125000e+03 | 1.125000e+03 | 2.147484e+09 | ▇▁▁▁▁ |
| minimum_nights_avg_ntm | 14 | 1.00 | 2.237000e+01 | 4.616000e+01 | 1.000000e+00 | 2.000000e+00 | 9.300000e+00 | 3.000000e+01 | 1.250000e+03 | ▇▁▁▁▁ |
| maximum_nights_avg_ntm | 14 | 1.00 | 1.571531e+06 | 5.604246e+07 | 1.000000e+00 | 3.650000e+02 | 1.125000e+03 | 1.125000e+03 | 2.147484e+09 | ▇▁▁▁▁ |
| availability_30 | 0 | 1.00 | 9.760000e+00 | 1.186000e+01 | 0.000000e+00 | 0.000000e+00 | 3.000000e+00 | 2.200000e+01 | 3.000000e+01 | ▇▁▁▁▃ |
| availability_60 | 0 | 1.00 | 2.113000e+01 | 2.368000e+01 | 0.000000e+00 | 0.000000e+00 | 9.000000e+00 | 4.500000e+01 | 6.000000e+01 | ▇▁▂▁▃ |
| availability_90 | 0 | 1.00 | 3.368000e+01 | 3.569000e+01 | 0.000000e+00 | 0.000000e+00 | 2.000000e+01 | 7.000000e+01 | 9.000000e+01 | ▇▂▁▂▃ |
| availability_365 | 0 | 1.00 | 1.402600e+02 | 1.420000e+02 | 0.000000e+00 | 0.000000e+00 | 8.900000e+01 | 2.890000e+02 | 3.650000e+02 | ▇▂▂▂▅ |
| number_of_reviews | 0 | 1.00 | 2.586000e+01 | 5.662000e+01 | 0.000000e+00 | 1.000000e+00 | 5.000000e+00 | 2.400000e+01 | 1.842000e+03 | ▇▁▁▁▁ |
| number_of_reviews_ltm | 0 | 1.00 | 7.740000e+00 | 1.829000e+01 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 7.000000e+00 | 1.093000e+03 | ▇▁▁▁▁ |
| number_of_reviews_l30d | 0 | 1.00 | 4.300000e-01 | 1.690000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 1.420000e+02 | ▇▁▁▁▁ |
| review_scores_rating | 10304 | 0.76 | 4.640000e+00 | 7.200000e-01 | 0.000000e+00 | 4.600000e+00 | 4.830000e+00 | 5.000000e+00 | 5.000000e+00 | ▁▁▁▁▇ |
| review_scores_accuracy | 10739 | 0.75 | 4.750000e+00 | 4.700000e-01 | 0.000000e+00 | 4.700000e+00 | 4.890000e+00 | 5.000000e+00 | 5.000000e+00 | ▁▁▁▁▇ |
| review_scores_cleanliness | 10729 | 0.75 | 4.640000e+00 | 5.400000e-01 | 0.000000e+00 | 4.500000e+00 | 4.800000e+00 | 5.000000e+00 | 5.000000e+00 | ▁▁▁▁▇ |
| review_scores_checkin | 10743 | 0.75 | 4.810000e+00 | 4.200000e-01 | 0.000000e+00 | 4.800000e+00 | 4.950000e+00 | 5.000000e+00 | 5.000000e+00 | ▁▁▁▁▇ |
| review_scores_communication | 10734 | 0.75 | 4.810000e+00 | 4.400000e-01 | 0.000000e+00 | 4.800000e+00 | 4.960000e+00 | 5.000000e+00 | 5.000000e+00 | ▁▁▁▁▇ |
| review_scores_location | 10746 | 0.75 | 4.730000e+00 | 4.200000e-01 | 0.000000e+00 | 4.640000e+00 | 4.850000e+00 | 5.000000e+00 | 5.000000e+00 | ▁▁▁▁▇ |
| review_scores_value | 10746 | 0.75 | 4.640000e+00 | 5.000000e-01 | 0.000000e+00 | 4.530000e+00 | 4.770000e+00 | 4.960000e+00 | 5.000000e+00 | ▁▁▁▁▇ |
| calculated_host_listings_count | 0 | 1.00 | 2.405000e+01 | 8.087000e+01 | 1.000000e+00 | 1.000000e+00 | 1.000000e+00 | 4.000000e+00 | 5.260000e+02 | ▇▁▁▁▁ |
| calculated_host_listings_count_entire_homes | 0 | 1.00 | 1.295000e+01 | 6.328000e+01 | 0.000000e+00 | 0.000000e+00 | 1.000000e+00 | 1.000000e+00 | 5.260000e+02 | ▇▁▁▁▁ |
| calculated_host_listings_count_private_rooms | 0 | 1.00 | 1.098000e+01 | 4.720000e+01 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 2.000000e+00 | 3.940000e+02 | ▇▁▁▁▁ |
| calculated_host_listings_count_shared_rooms | 0 | 1.00 | 6.000000e-02 | 6.000000e-01 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 1.300000e+01 | ▇▁▁▁▁ |
| reviews_per_month | 10304 | 0.76 | 1.170000e+00 | 1.790000e+00 | 1.000000e-02 | 1.400000e-01 | 5.200000e-01 | 1.670000e+00 | 8.661000e+01 | ▇▁▁▁▁ |
Research question(s)
How does Airbnb listing prices depend on rating of listing, location of listing, amenities included in the listing, and host response time?
How do characteristics (i.e., ratings and descriptions) of listings and of hosts affect the prices of listings?
What are the most popular neighborhoods for Airbnb listings and how does this popularity vary by listing type and price?
Data collection and cleaning
We see from skim that there are several variables that have missing values, including neighborhood_overview, host_location, host_about and host_neighbourhood among others. Although we want to look at host characteristics, we believe that the columns host_location and host_neighbourhood will not be of too much use in our analysis, so we can ignore it. For other columns, we will appropriately deal with missing values.
Furthermore, we recognize that first_review and last_review both have 10,304 missing values. This probably means that 10,304 listings don’t have any reviews. It might be interesting to subset these listings to see what factors affect the listing prices of Airbnb listings that do not have reviews.
no_reviews <- airbnb_data |>
filter(is.na(first_review))Price is not numeric in the dataset, so we change the format to numeric.
airbnb_data <- airbnb_data |>
mutate(price = parse_number(price))Below we outline how we cleaned and parsed through the main dataset airbnb_data to look at several major components: location, availability, amenities, host characteristics, and listing characteristics.
Location
For my data cleaning, I have chosen to filter out all columns related to the location of each Airbnb listing, including its latitude, longitude, and neighborhood located in NYC among other things. While it was clear from the start that I would likely not use most of the variable I selected, I believe that keeping in mind these other forms of listing location could be useful down the line. I also obviously included the price of said listings, mutating a new column that make the price into a raw number instead of a character string.
# Data cleaning: main cleaning was $ signs and selecting necessary variables
df_location_price <- airbnb_data |>
select(
latitude, longitude, neighbourhood, neighbourhood_cleansed,
neighbourhood_group_cleansed, price
) |>
mutate(numb_dollar = as.numeric(gsub("\\$|,", "", price)))
df_location_price# A tibble: 42,931 × 7
latitude longitude neighbourhood neighbourhood_cleansed
<dbl> <dbl> <chr> <chr>
1 40.6 -73.9 <NA> Canarsie
2 40.6 -73.9 <NA> Canarsie
3 40.5 -74.3 <NA> Tottenville
4 40.6 -74.0 <NA> Sheepshead Bay
5 40.9 -73.9 The Bronx, New York, United States North Riverdale
6 40.8 -73.8 Queens, New York, United States Flushing
7 40.8 -73.8 <NA> Whitestone
8 40.5 -74.2 <NA> Prince's Bay
9 40.7 -73.8 <NA> Richmond Hill
10 40.9 -73.9 RIVERDALE, New York, United States Kingsbridge
# ℹ 42,921 more rows
# ℹ 3 more variables: neighbourhood_group_cleansed <chr>, price <dbl>,
# numb_dollar <dbl>Availability
In our dataset, we have several columns that talk about the availability of Airbnb listings. availability_* tells us the availability of the listing * days in the future as determined by the calendar. We should keep in mind that a listing may not be available because it has been booked by a guest or blocked by the host.
It is interesting to extract the month and year for the availability for analysis on the availability.
# Extract month and year from last_review column
airbnb_data_availability <- airbnb_data |>
mutate(month_year = floor_date(as.Date(last_review), unit = "month")) |>
select(id, price, availability_30, availability_60, availability_90, availability_365, month_year)Amenities
A major issue with amenities is that it is stored as a character list. We need to parse and clean this so that we can do more analysis.
amenities_df <- airbnb_data |>
# Create subset of Airbnb data pertaining to amenities
select(id, amenities) |>
# Replace any occurrences of square brackets with empty string
mutate(amenities = gsub("\\[|\\]", "", amenities)) |>
# Split the list by comma and make separate rows
separate_rows(amenities, sep = ", ") |>
# Unnest the list
unnest(amenities)
amenities_df# A tibble: 1,121,291 × 2
id amenities
<dbl> <chr>
1 8.02e17 "\"50\\\" TV\""
2 8.02e17 "\"Bathtub\""
3 8.02e17 "\"Microwave\""
4 8.02e17 "\"Free driveway parking on premises\""
5 8.02e17 "\"Laundromat nearby\""
6 8.02e17 "\"Kitchen\""
7 8.02e17 "\"Refrigerator\""
8 8.02e17 "\"Central air conditioning\""
9 8.02e17 "\"Smoke alarm\""
10 8.02e17 "\"Central heating\""
# ℹ 1,121,281 more rows# Save a csv copy for future purposes
# write.csv(amenities_df, "data/airbnb_data/amenities_data.csv", row.names=FALSE)Now that we have parsed the amenities out of its list format, there is another problem. How the amenities are reported in the dataset is dependent on how the host described their list of amenities. In other words, there is no standardization on how amenities are reported. That is why we have multiple variations of the same amenity. For example, we have several variations of “HDTV” depending on the size of the HDTV and the applications (Amazon Prime, Netflix, etc.) that come with it among other factors. Similarly, many listings have “fast wifi” listed as an amenity, but we see variations depending on the speed listed.
Is there a way to consolidate the different variations? One way is to conduct partial matching with some desired amenity (the below code looks for “fast wifi”) and create a new column to store a boolean that describes whether the listing has that desired amenity or not.
fast_wifi <- amenities_df |>
mutate(fast_wifi = str_detect(amenities, regex("fast wifi", ignore_case = TRUE)))
fast_wifi# A tibble: 1,121,291 × 3
id amenities fast_wifi
<dbl> <chr> <lgl>
1 8.02e17 "\"50\\\" TV\"" FALSE
2 8.02e17 "\"Bathtub\"" FALSE
3 8.02e17 "\"Microwave\"" FALSE
4 8.02e17 "\"Free driveway parking on premises\"" FALSE
5 8.02e17 "\"Laundromat nearby\"" FALSE
6 8.02e17 "\"Kitchen\"" FALSE
7 8.02e17 "\"Refrigerator\"" FALSE
8 8.02e17 "\"Central air conditioning\"" FALSE
9 8.02e17 "\"Smoke alarm\"" FALSE
10 8.02e17 "\"Central heating\"" FALSE
# ℹ 1,121,281 more rowsCan we make this process somewhat more reproducible and flexible? What if we want to look at other amenities? Below, we check if a listing has “wifi,” “parking,” “dryer”, “washer,” and “kitchen” listed in their list of amenities. Certainly, this list of amenities can be changed depending on our research scope later.
# Create character vector of amenities of interest
essentials <- c("wifi", "parking", "dryer", "washer", "kitchen")
# Duplicate amenities_df
essential_amenities_df <- data.frame(amenities_df)
# Iterate over amenities in essentials
for (amenity in essentials) {
essential_amenities_df <- essential_amenities_df |>
# Create boolean column
mutate(!!amenity :=
str_detect(
essential_amenities_df$amenities,
regex(amenity, ignore_case = TRUE)
))
}
# Group by listing
listing_esential_amenitites <- essential_amenities_df |>
group_by(id) |>
summarise(
wifi = any(wifi),
parking = any(parking),
dryer = any(dryer),
washer = any(washer),
kitchen = any(kitchen)
) |>
pivot_longer(
cols = -id,
names_to = "amenities",
values_to = "listed"
)
listing_esential_amenitites# A tibble: 214,655 × 3
id amenities listed
<dbl> <chr> <lgl>
1 2595 wifi TRUE
2 2595 parking TRUE
3 2595 dryer TRUE
4 2595 washer FALSE
5 2595 kitchen TRUE
6 5121 wifi TRUE
7 5121 parking FALSE
8 5121 dryer FALSE
9 5121 washer FALSE
10 5121 kitchen TRUE
# ℹ 214,645 more rowsSince we have the listing identifier in listing_esential_amenitites, we can merge listing_esential_amenitites with our main dataset to gather information on price and learn about how amenities affect listing prices.
Host characteristics
Another possible area of inquiry within this dataset is looking at a variety of host characteristics and how they possibly affect the price of a listing. The first step in doing so is making a dataframe with all the necessary yet pertinent variables that have to do with a host such as if they are a super host, their acceptance rate, etc.
Since a host has many listings detailed in the main dataset, we often use the distinct() function to remove repeated host_ids when necessary; if price is a variable for these instances, we average the price of all listings per each individual host.
# Dataframe with all variables to do with host characteristics
host_char <- airbnb_data |>
select(
host_id,
host_is_superhost,
host_identity_verified,
host_has_profile_pic,
host_since,
host_response_time,
host_response_rate,
host_acceptance_rate,
host_listings_count,
review_scores_communication,
price
)
host_char# A tibble: 42,931 × 11
host_id host_is_superhost host_identity_verified host_has_profile_pic
<dbl> <lgl> <lgl> <lgl>
1 495455523 FALSE FALSE TRUE
2 488760226 FALSE TRUE TRUE
3 461263600 FALSE FALSE FALSE
4 475699129 TRUE TRUE TRUE
5 397288055 FALSE TRUE TRUE
6 239139334 FALSE TRUE TRUE
7 426682883 FALSE FALSE FALSE
8 77290831 FALSE TRUE TRUE
9 51426218 FALSE TRUE TRUE
10 21444167 TRUE TRUE TRUE
# ℹ 42,921 more rows
# ℹ 7 more variables: host_since <date>, host_response_time <chr>,
# host_response_rate <chr>, host_acceptance_rate <chr>,
# host_listings_count <dbl>, review_scores_communication <dbl>, price <dbl>A subset of the aforementioned dataframe has to do with the number of listings a host has and how that might impact the average price of a host’s listings. To do so, we need to select host_listings_count and the price. We make sure to omit any NA values for visual easability purposes.
# Data frame with each host, their total num of listings
# and their average price
host_list <- host_char |>
select(host_id, host_listings_count, price) |>
group_by(host_id) |>
mutate(avg_price_host = mean(price)) |>
distinct(host_id, .keep_all = TRUE) |>
na.omit(host_listings_count)
host_list# A tibble: 27,450 × 4
# Groups: host_id [27,450]
host_id host_listings_count price avg_price_host
<dbl> <dbl> <dbl> <dbl>
1 495455523 1 143 143
2 488760226 2 30 50
3 461263600 1 157 157
4 475699129 7 89 75.7
5 397288055 1 125 125
6 239139334 3 63 59.7
7 426682883 1 82 82
8 77290831 1 118 118
9 51426218 10 49 146.
10 21444167 2 115 104.
# ℹ 27,440 more rowsAnother potential aspect to look at is whether certain host attributes can be used as a predictive measure in determining if a host is a super host. For this, we can look at the variables host_is_superhost, host_identity_verified, and host_has_profile_pic. Furthermore, for future possible modeling methods, changing some variables to a quantifiable number is necessary, which can be seen below:
# Data frame with each host, if they are a super host,
# if they have a profile picture, and if their identity is verified
superhost <- host_char |>
select(
host_id,
host_is_superhost,
host_identity_verified,
host_has_profile_pic
) |>
distinct(host_id, .keep_all = TRUE) |>
mutate(
host_is_superhost = if_else(host_is_superhost == "TRUE", 1, 0),
host_identity_verified = if_else(host_identity_verified == "TRUE", 1, 0),
host_has_profile_pic = if_else(host_has_profile_pic == "TRUE", 1, 0)
)
superhost# A tibble: 27,455 × 4
host_id host_is_superhost host_identity_verified host_has_profile_pic
<dbl> <dbl> <dbl> <dbl>
1 495455523 0 0 1
2 488760226 0 1 1
3 461263600 0 0 0
4 475699129 1 1 1
5 397288055 0 1 1
6 239139334 0 1 1
7 426682883 0 0 0
8 77290831 0 1 1
9 51426218 0 1 1
10 21444167 1 1 1
# ℹ 27,445 more rowsWithin the main Airbnb dataframe is a variable called review_scores_communication. This can be interesting to use against price as consumers on the Airbnb website definitely want to know how communicative a host is when choosing a listing.
# Data frame with host's communication rating and price
rating <- host_char |>
select(
host_id,
review_scores_communication,
price
)
# Find average price of listings per host
host_rating <- host_char |>
select(host_id,
review_scores_communication,
price) |>
# Find average price of listings per host
group_by(host_id) |>
mutate(price = mean(price)) |>
# Remove repeat of same hosts
distinct(host_id, .keep_all = TRUE) |>
na.omit(rating)
host_rating# A tibble: 21,412 × 3
# Groups: host_id [21,412]
host_id review_scores_communication price
<dbl> <dbl> <dbl>
1 488760226 4.92 50
2 475699129 5 75.7
3 397288055 4.88 125
4 239139334 4.78 59.7
5 77290831 5 118
6 51426218 5 146.
7 21444167 4.93 104.
8 486718434 5 179
9 479109924 4.82 172
10 179951095 5 94
# ℹ 21,402 more rowsOne last area to look, at in tandem with host characteristics, might have to do with a host’s acceptance rate. Here we select host_acceptance_rate, price, and host_is_superhost to see how acceptance rate varies against price and how it might be influenced by them being a super host or not.
# Data frame with host's acceptance rate, price, and if they
# are a super host
accept <- host_char |>
select(
host_id,
host_acceptance_rate,
price,
host_is_superhost
) |>
group_by(host_id) |>
mutate(price = mean(price)) |>
distinct(host_id, .keep_all = TRUE)
# Make character N/A a logical NA value
accept[accept == "N/A"] <- NA
# Omit NA values
accept <- accept |>
na.omit(host_acceptance_rate) |>
# Change acceptance rate to numbers
mutate(
host_acceptance_rate = substr(host_acceptance_rate, 0, nchar(host_acceptance_rate)),
host_acceptance_rate = parse_number(host_acceptance_rate)
) |>
# Change super host column to categorical variable
mutate(host_is_superhost = if_else(host_is_superhost == "TRUE", "Superhosts", "Not Superhost"))
# Plot listings versus price dataset
ggplot(host_list,
mapping = aes(x = avg_price_host, y = host_listings_count)
) +
geom_point() +
theme_minimal() +
scale_x_continuous(limits = quantile(host_list$price, c(0.1, 0.95))) +
labs(
title = "# of listings vs average price",
x = "Average price (per host)",
y = "# of listings (per host)"
)Warning: Removed 3776 rows containing missing values (`geom_point()`).
# Plot host rating and price of listings
ggplot(rating,
mapping = aes(x = price, y = review_scores_communication)
) +
geom_point() +
theme_minimal() +
scale_x_continuous(limits = quantile(rating$price, c(0.1, 0.95))) +
labs(
title = "Host communication rating vs price",
x = "Average price (per host)",
y = "Host acceptance rate"
)Warning: Removed 14370 rows containing missing values (`geom_point()`).
# Plot acceptance rate and price and facet by super hosts
ggplot(accept,
mapping = aes(x = price, y = host_acceptance_rate)
) +
geom_col(width = 15, fill = "lightblue") +
facet_wrap(vars(host_is_superhost)) +
theme_bw() +
scale_x_continuous(
limits = quantile(accept$price, c(0.1, 0.95)),
labels = label_dollar()
) +
scale_y_continuous(labels = label_percent(scale = .001)) +
labs(
title = "Host acceptance rate vs price",
x = "Average price (per host)",
y = "Host acceptance rate"
)Warning: Removed 2392 rows containing missing values (`position_stack()`).Warning: `position_stack()` requires non-overlapping x intervals
`position_stack()` requires non-overlapping x intervalsWarning: Removed 539 rows containing missing values (`geom_col()`).
Listing characteristics
There are a few variables that characterize a listing in our main dataset. To clean and parse the data more easily, we create smaller subsets of the data. Below we create two dataframes: 1) price and room type and 2) price and ratings. Not all listings have a rating, so we also omit observations with NA for rating. Similarily, not all listings have a value for bedrooms. This might be because there are studio apartments and other forms of non-traditional accommodations listed in Airbnb.
# Create a dataframe for price and room type
room_type_price <- airbnb_data |>
select(id, price, room_type)
# Create a dataframe for price and ratings
ratings_price <- airbnb_data |>
select(id, price, review_scores_rating) |>
drop_na()
# Create a dataframe for price and number of bedrooms
bedroom_price <- airbnb_data |>
select(id, price, bedrooms) |>
drop_na()Data description
The airbnb_data dataset comes from Inside Airbnb (http://insideairbnb.com/get-the-data/), an open platform that provides data on Airbnb listings in different locations around the world.
The objective of Inside Airbnb is to empower communities by providing them with information and data regarding the impact of Airbnb on residential areas. Their mission is to enable communities to make informed decisions and have control over the practice of renting homes to tourists, with the ultimate goal of achieving a vision where data is used to shape this industry.
The data gives NYC listings from the first quarter in 2023. It is aggregated through Airbnb’s public information on their website and shows all listings from that respective quarter at the particular time of publication (i.e., for this particular dataset, March 6, 2023).
In terms of what processes might have influenced what data was observed and what was not, there is not much, if any. The data utilizes public information compiled from the Airbnb website, so, if a listing is on the website at the time of scraping, it will be on the dataset.
No private information is being used: names, photographs, listings, and review details are all public. Furthermore, not much preprocessing was done (or explained) on the data. Evidence of this can be seen from the data. For example, price is noted as a chr, which is likely due to it being directly scraped from the webpage.
All the Airbnb data scraped by Inside Airbnb is public, so all Airbnb hosts should be aware that their data and information can be scraped and used for other purposes.
In airbnb_data, the observations (rows) are different Airbnb listings in NYC and the attributes (columns) are various variables that describe the listing. Some columns include price, host_is_superhost, room_type, and review_scores_rating.
Above, we produced several subsets of the main dataset including no_reviews, df_location_price, amenities_df, and room_type_price among other dataframes.
Data limitations
There are several limitations with our data:
With our current dataset, we cannot do a time-series analysis on prices since the prices listed in
airbnb_datais valid for the one day the data was scraped. There are more .csv files on Inside Airbnb that we can download and merge to conduct a time-series analysis on prices.We can only do analysis on Airbnb listings in NYC. How about Chicago? San DIego? London? Trends we find in NYC may not be applicable in other cities.
Exploratory data analysis
Location
The next step was the exploratory analysis. For the sake of understanding the general trend of each region of NYC, I focused mainly on the column neighbourhood_group_cleansed, the broadest categorical variable for listing location, and compared it to price of the listings. However, I immediately noticed that there were a few exceptionally expensive listings within this data set, so I first tried boxploting the logarithmic prices, so that the values were readable. I also counted the number of actually listings per region of NYC so that I could understand the boxplots better.
# Exploratory (while my main interest is in neighbourhood_group_cleansed, I want to include other relevant location data in this for future use)
df_location_price |>
mutate(neighbourhood_group_cleansed = fct_reorder(neighbourhood_group_cleansed, numb_dollar, .desc = TRUE)) |>
ggplot(aes(neighbourhood_group_cleansed, fill = neighbourhood_group_cleansed)) +
geom_bar(show.legend = FALSE) +
labs(
x = "New York neighborhoods",
y = "Count",
title = "Priced Airbnb listing count within New York neighborhoods"
) +
theme_minimal()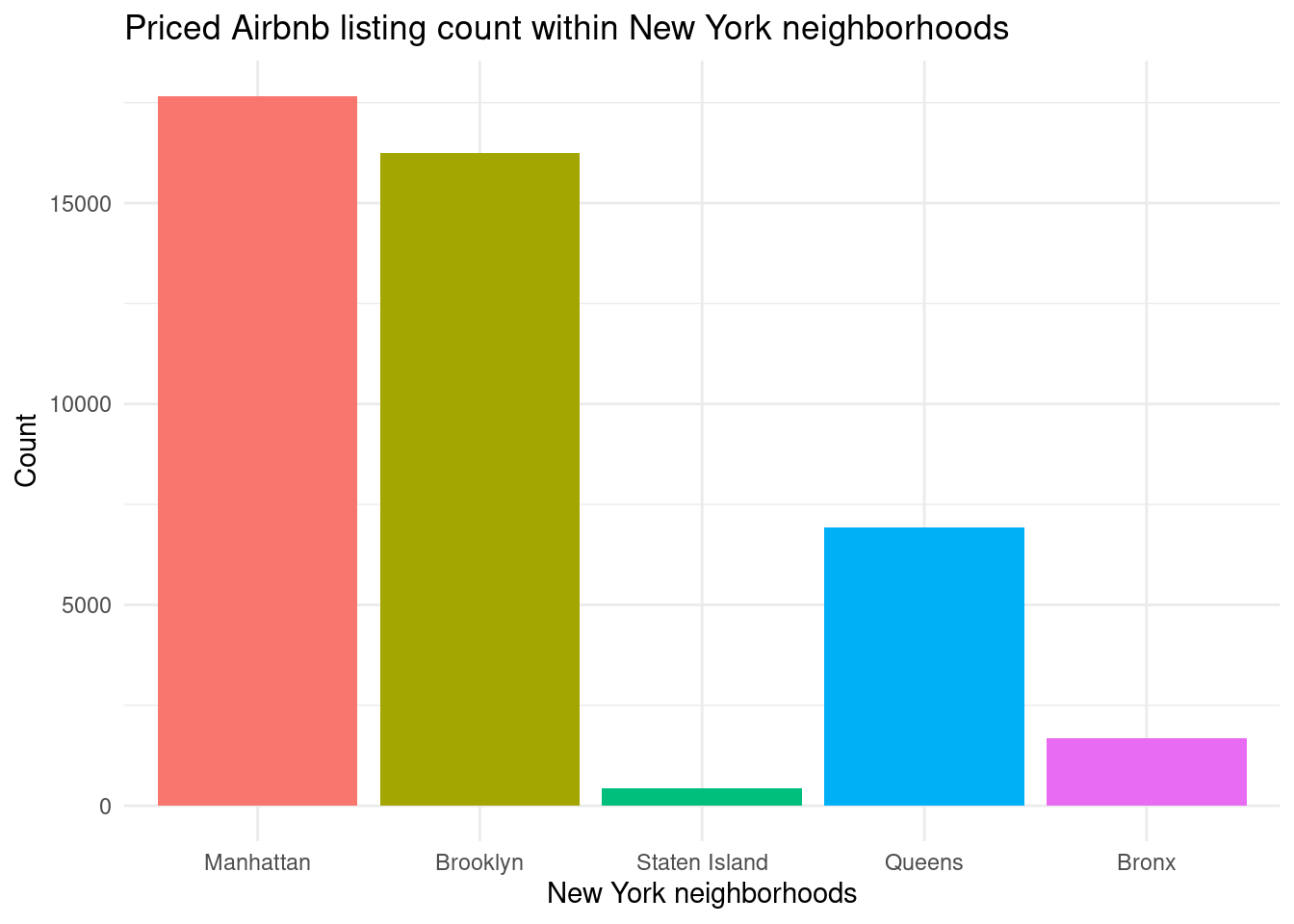
df_location_price |>
mutate(neighbourhood_group_cleansed = fct_reorder(neighbourhood_group_cleansed, numb_dollar, .desc = TRUE)) |>
ggplot(aes(log(numb_dollar), neighbourhood_group_cleansed, fill = neighbourhood_group_cleansed)) +
geom_boxplot(show.legend = FALSE) +
theme_minimal() +
labs(
y = "New York neighborhoods",
x = "(logarithmic) Listing prices",
title = "Airbnb listing prices within New York neighborhoods"
) +
scale_x_continuous(labels = label_dollar(scale_cut = cut_short_scale()))Warning: Removed 27 rows containing non-finite values (`stat_boxplot()`).
However, this set up is likely not going to be helpful in understanding any other patterns other than the raw median / IQR / or outliers of the data, as the axis is only accounting for a very long and thing tail skewing the data heavily to the right. Because of this, I believe that we should have a cut off to look more closely at the majority of data points.
# Exploratory V2 (Cutting off at $500 per night. I am fully aware that 500 is an arbitrary number and that we should decide a specific percentile in the future. The number was chosen to prove my point)
# reasoning for cut-off: https://airbtics.com/airbnb-occupancy-rates-in-new-york-city/, histogram: patterns we could not be able to see if we didn't cut off the huge skewed tail.
df_location_price |>
mutate(neighbourhood_group_cleansed = fct_reorder(neighbourhood_group_cleansed, numb_dollar, .desc = TRUE)) |>
filter(numb_dollar < 500) |>
ggplot(aes(numb_dollar, neighbourhood_group_cleansed, fill = neighbourhood_group_cleansed)) +
geom_boxplot(show.legend = FALSE) +
theme_minimal() +
labs(
y = "New York neighborhoods",
x = "Listing prices",
title = "Airbnb listing prices within New York neighborhoods (< $500/night)"
) +
scale_x_continuous(labels = label_dollar(scale_cut = cut_short_scale()))
df_location_price |>
mutate(neighbourhood_group_cleansed = fct_reorder(neighbourhood_group_cleansed, numb_dollar, .desc = TRUE)) |>
filter(numb_dollar < 500) |>
ggplot(aes(numb_dollar, fill = neighbourhood_group_cleansed)) +
geom_histogram(show.legend = FALSE, binwidth = 8) +
facet_wrap(facet = vars(neighbourhood_group_cleansed)) +
labs(
y = "Count",
x = "Listing prices",
title = "Airbnb listing prices within New York neighborhoods (< $500/night)"
) +
scale_x_continuous(labels = label_dollar(scale_cut = cut_short_scale())) +
theme_minimal()
For the sake of my argument, I’m cutting off the data at $500 per night for these two graphs. For example, the histogram shows patterns we could not be able to see if we didn’t cut off the huge skewed tail, like how there appears to be multiple spikes in listings at rounded values ($100 per night, $200, $300, etc). I am fully aware that 500 is an arbitrary number and that we should decide a specific percentile in the future.
Availability
# Create scatterplot to visualize relationship between availability and price
ggplot(airbnb_data_availability, aes(x = availability_30, y = price)) +
geom_point(alpha = 0.5) +
labs(x = "Availability (30 days)", y = "Price (USD)") +
ggtitle("Relationship between Availability and Price") +
theme(plot.title = element_text(hjust = 0.5))
# Create scatterplot to visualize relationship between availability_365 and price by month/year
ggplot(airbnb_data_availability, aes(x = availability_365, y = price, color = month_year)) +
geom_point(alpha = 0.5) +
labs(x = "Availability (365 days)", y = "Price (USD)", color = "Month/Year") +
ggtitle("Relationship between Availability and Price by Month/Year") +
theme(plot.title = element_text(hjust = 0.5))
# Create boxplot to compare price distribution across availability periods
airbnb_data |>
select(
price, availability_30, availability_60, availability_90,
availability_365
) |>
pivot_longer(cols = -price, names_to = "availability_period", values_to = "availability") |>
ggplot(aes(x = availability_period, y = price)) +
geom_boxplot(alpha = 0.5) +
labs(x = "Availability Period", y = "Price (USD)") +
ggtitle("Price Distribution by Availability Period") +
theme(plot.title = element_text(hjust = 0.5))
The first scatterplot shows the relationship between availability in the next 30 days and price. The second scatterplot shows the relationship between availability in the next 365 days and price, with each point colored by the month/year extracted from the “last_review” column.
Amenities
We can visualize the top 20 amenities listed in Airbnb listings.
amenities_df |>
group_by(amenities) |>
count() |>
arrange(desc(n)) |>
head(20) |>
ggplot(mapping = aes(x = n, y = fct_reorder(amenities, n))) +
geom_col() +
labs(
x = "Count",
y = "Amenities",
title = "Top 20 amenities listed in Airbnb rentals in NYC, March 2023"
) +
theme_minimal()
Upon analyzing the most frequently mentioned amenities in Airbnb listings in New York City, we observe that “Wifi” is the most common. Interestingly, “Dedicated workspace” also appears among the top 20 amenities, which may be attributed to the city’s status as a major economic hub. This observation raises the question of whether there is significant demand for Airbnb accommodations among travelling employees who require a comfortable and productive workspace while away from their home offices.
Earlier, we created fast_wifi, which outlines whether a listing has “fast wifi” listed in its list of amenities. Is there a trend between having fast wifi listed and listing price?
# Merge fast_wifi with price
fast_wifi_price <- airbnb_data |>
select(id, price) |>
merge(fast_wifi)
# Calculate mean listing price, group by fast_wifi
fast_wifi_price |>
group_by(fast_wifi) |>
summarise(
count = n(),
mean_price = mean(price)
)# A tibble: 2 × 3
fast_wifi count mean_price
<lgl> <int> <dbl>
1 FALSE 1118867 214.
2 TRUE 2424 217.We see that only around 2,000 listings out of over 40,000 listings in NYC advertise “fast wifi” as an amenity. Surprisingly, we do not see a significant difference in the mean listing price of listings that advertise “fast wifi” and those that do not. This finding suggests that the provision of Wifi is no longer a unique or distinguishing factor, and has become an essential and expected amenity in an Airbnb accommodation.
essential_count <- listing_esential_amenitites |>
group_by(amenities, listed) |>
count()
essential_pct <- essential_count |>
group_by(amenities) |>
mutate(pct = n / sum(n))
essential_pct |>
ggplot(aes(x = str_to_title(amenities), y = pct, fill = listed)) +
geom_bar(stat = "identity") +
labs(
x = "Amenities",
y = "Percentage of listings",
fill = "Listed",
title = "A visual guide to essential Airbnb amenities in NYC",
subtitle = "Kitchen and Wifi are the two most listed essential amenities"
) +
scale_y_continuous(labels = label_percent()) +
theme_minimal()
Host characteristics
Here we can visualize if the number of listings a host has affects their average price. From the graph shown below, it looks like there isn’t necessarily a correlation between the two variables:
# Plot listings versus price dataset
ggplot(host_list,
mapping = aes(x = avg_price_host, y = host_listings_count)
) +
geom_point() +
theme_minimal() +
scale_x_continuous(limits = quantile(host_list$price, c(0.1, 0.95))) +
labs(
title = "# of listings vs average price",
x = "Average price (per host)",
y = "# of listings (per host)"
)Warning: Removed 3776 rows containing missing values (`geom_point()`).
Here we visualize a host’s communication rating and their average price per listing. It looks like most hosts have a rating above 4. Even then, the prices of listings vary throughout.
# Plot host rating and price of listings
ggplot(host_rating,
mapping = aes(x = price, y = review_scores_communication)) +
geom_point() +
theme_minimal() +
scale_x_continuous(limits = quantile(host_rating$price, c(0.1, 0.95))) +
labs(title = "Host communication rating vs price",
x = "Average price (per host)",
y = "Host acceptance rate")Warning: Removed 3170 rows containing missing values (`geom_point()`).
Here we graph a host’s acceptance rate against their average listing price and group it by whether or not the host is a super host. We see that between both super hosts and non-super hosts, as the average price of listings per host goes up, their acceptance rate goes down. This is obvious as both graphs are right-skewed.
# Plot acceptance rate and price and facet by super hosts
ggplot(accept,
mapping = aes(x = price, y = host_acceptance_rate)) +
geom_col(width = 15, fill="lightblue") +
facet_wrap(vars(host_is_superhost)) +
theme_bw() +
scale_x_continuous(limits = quantile(accept$price, c(0.1, 0.95)),
labels = label_dollar()) +
scale_y_continuous(labels = label_percent(scale = .001)) +
labs(title = "Host acceptance rate vs price",
x = "Average price (per host)",
y = "Host acceptance rate")Warning: Removed 2392 rows containing missing values (`position_stack()`).Warning: `position_stack()` requires non-overlapping x intervals
`position_stack()` requires non-overlapping x intervalsWarning: Removed 539 rows containing missing values (`geom_col()`).
Listing characteristics
Let’s first see how many listings there are in each available room type.
room_type_price |>
group_by(room_type) |>
count() |>
ggplot(aes(x = room_type, y = n)) +
geom_col() +
labs(
x = "Room type",
y = "Count"
) +
theme_minimal()
We see that the “Entire home/apt” and “Private room” room types are most frequent. How does price vary with the room types?
# Graph Price vs. Room type
room_type_price |>
group_by(room_type) |>
ggplot(aes(x = room_type, y = price)) +
geom_boxplot() +
scale_y_continuous(limits = quantile(room_type_price$price, c(0.1, 0.9))) +
labs(x = "Room Type", y = "Price") +
theme_minimal()Warning: Removed 8326 rows containing non-finite values (`stat_boxplot()`).
We see that the median prices of hotel rooms are most expensive, followed by entire home/apt options, and followed by private room and shared room options.
Another characteristic of a listing is the number of bedrooms it has, given by column bedrooms in airbnb_data. Let’s first see the distribution of number of bedrooms.
bedroom_price |>
ggplot(aes(x = bedrooms)) +
geom_histogram() +
labs(
x = "Number of bedrooms",
y = "Count"
) +
theme_minimal()`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
We see that the histogram is very much right-skewed and most listings have less than four bedrooms. How does price relate to the number of bedrooms?
# Graph Price vs. bedrooms
bedroom_price |>
ggplot(aes(x = bedrooms, y = price)) +
geom_jitter() +
labs(x = "Bedrooms", y = "Price") +
theme_minimal()
There are some outliers that make the scatterplot look weird. Let’s try to 1) only take listings up to the 75th percentile in prices and 2) only see listings with less than four bedrooms.
bedroom_price |>
filter(bedrooms <= 4) |>
ggplot(aes(y = price)) +
geom_boxplot() +
facet_wrap(vars(bedrooms), ncol = 4, nrow = 1) +
scale_y_continuous(limits = quantile(bedroom_price$price, c(0, 0.75))) +
labs(
y = "Price"
) +
theme_minimal() +
theme(axis.text.x = element_blank())Warning: Removed 9547 rows containing non-finite values (`stat_boxplot()`).
From the boxplots above, we see that two- and three-bedroom options are generally more expensive.
# Fit linear regression model
price_bedroom_fit <- linear_reg() |>
fit(price ~ bedrooms, data = bedroom_price)
tidy(price_bedroom_fit)# A tibble: 2 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) 33.5 8.02 4.18 2.87e- 5
2 bedrooms 118. 4.99 23.6 2.47e-122glance(price_bedroom_fit)# A tibble: 1 × 12
r.squared adj.r.squared sigma statistic p.value df logLik AIC BIC
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 0.0141 0.0140 780. 557. 2.47e-122 1 -315508. 6.31e5 6.31e5
# ℹ 3 more variables: deviance <dbl>, df.residual <int>, nobs <int>bedroom_price |>
summarize(
c = cor(bedrooms, price)
)# A tibble: 1 × 1
c
<dbl>
1 0.119Another characteristic of a listing is the number of bathrooms it has, given by column bathrooms in airbnb_data. Let’s first see the distribution of number of bathrooms. We first need to tidy the data.
# Remove rows with missing values in Bedrooms or Bathrooms columns
listing <- airbnb_data %>%
select(id, price, neighbourhood_cleansed, neighbourhood_group_cleansed,
room_type, bedrooms, review_scores_rating, bathrooms_text) |>
filter(!is.na(bedrooms), !is.na(bathrooms_text))
# Extract number of bathrooms from bathrooms_text
listing$bathrooms <- str_extract(listing$bathrooms_text, "\\d+")
# Convert "shared" bathrooms to half a bathroom
listing$bathrooms <- ifelse(str_detect(listing$bathrooms_text, "shared"),
as.numeric(listing$bathrooms)/2,
listing$bathrooms)
# Convert "private" bathrooms to numeric
listing$bathrooms <- ifelse(str_detect(listing$bathrooms_text, "private"),
as.numeric(listing$bathrooms),
listing$bathrooms)
# Change the bathrooms from charaters to numeric values
listing <- listing |>
mutate(bathrooms = as.numeric(bathrooms))listing |>
ggplot(aes(x = bathrooms)) +
geom_histogram(binwidth = 1) +
labs(
x = "Number of bathrooms",
y = "Count",
title = "Count of number of bathrooms on Airbnb NYC listing"
) +
theme_minimal()Warning: Removed 52 rows containing non-finite values (`stat_bin()`).
We can see that most listings have 1 bathroom, then half bathroom, and then 2 bathrooms. The number of listings with other numbers of bathrooms is not too small to be representative.
listing |>
filter(bathrooms <= 4) |>
ggplot(aes(y = price)) +
geom_boxplot() +
facet_wrap(vars(bathrooms), ncol = 7, nrow = 1) +
scale_y_continuous(limits = quantile(listing$price, c(0, 0.9))) +
labs(x = "Bathrooms",
y = "Price",
title = "Price vs. Bathroom numbers in NYC") +
theme(axis.text.x = element_blank()) +
theme_minimal()Warning: Removed 3861 rows containing non-finite values (`stat_boxplot()`).
Questions for reviewers
Some questions we have are:
Are our research questions okay? Do we need to be more specific? More broad?
Can you think of other variables that we can include in our analysis, or you think would be interesting to look into?