Covid Policies Data Across the United States
Exploratory data analysis
Research question(s)
Is there a correlation between a region’s political stance and the number of covid policies it has implemented?
Do different regions lean towards different policies?
Do certain regions tend towards state or county policies?
Data collection and cleaning
Have an initial draft of your data cleaning appendix. Document every step that takes your raw data file(s) and turns it into the analysis-ready data set that you would submit with your final project. Include text narrative describing your data collection (downloading, scraping, surveys, etc) and any additional data curation/cleaning (merging data frames, filtering, transformations of variables, etc). Include code for data curation/cleaning, but not collection.
Draft of data cleaning appendix:
- Delete “county” column: Because our research questions deal with regions and states, removing the county column would help reduce the information that we need to process as we do not intend on using it.
- Delete “source” column: Our data analysis and visualization will not require us to reference the source of the policy.
- Delete “fips_codes” column: In similar vain to the previous choice, a fip code stands for the “Federal Information Processing Standards,” and it is a five-digit code used to uniquely identify counties and in the United States. Because we will not be working with counties in our project, this information is not needed for analysis.
- Delete “geocoded_state” column: a geocode is a code that represents a geographic entity; in this case, it represents the geographic location of the state; since we intend to identify the potential patterns that we speculate through the state itself and the general region, we do not need the code of the specific physical location.
- Delete “total_phases” column: though this data could have been useful, in filtering for all the NA values out, it would get rid of too many observations since a significant number of rows for this column contain NA values.
- Rename “state_id” to just “state”: in doing this, it will ease our process of referencing the variable. The state_id variable is just the two-letter representation of the state itself.
- Filter out the NA rows: this is pretty self-explanatory; we do not want additional NA values to inhibit our data representation and analysis.
- Separate the dataset into two datasets based off of the “start_stop” column – one for “start” and another for “stop”: Separating the datasets into the start and stop values in the start_stop column will allow us to efficiently compare when each state or region starts and stops their policy. With the current arrangement, it is difficult to compare as the two values for each state are situated in the same column.
Data description
Have an initial draft of your data description section. Your data description should be about your analysis-ready data.
- What are the observations (rows) and the attributes (columns)?
- This dataset contains 11 columns and 4,218 rows. Each of the observations (rows) represents a different COVID-19 policy. Every observation is repeated twice since the dataset contains the start and end of every state and county COVID policy from March 2020 to December 2022. The columns of interest for our analysis are
state_idwhich denotes which state a policy occurred in,countywhich identifies the country that a policy occurred in,policy_levelwhich denotes whether a policy was implemented at a state or county level,datewhich is the date a policy was implemented on,policy_typewhich describes details of the COVID policy,start_stopwhich indicates if the row is the start or end of a policy,commentswhich are additional comments about the policy, andtotal_phaseswhich shows how many times the policy was reimplemented or changed.
- This dataset contains 11 columns and 4,218 rows. Each of the observations (rows) represents a different COVID-19 policy. Every observation is repeated twice since the dataset contains the start and end of every state and county COVID policy from March 2020 to December 2022. The columns of interest for our analysis are
- Why was this dataset created?
- This dataset was created to provide a standardized view of state and county policy orders (executive orders, ordinances, etc) for public release by the U.S Department of Health and Human services. This dataset is part of a large collection of HHS COVID-19-related datasets that aimed to distribute quality COVID-19 data to the public.
- Who funded the creation of the dataset?
- The data was collected and paid for by the U.S Department of Health and Human Services and transferred over to the HHS Office of the Chief Data Officer for public distribution. The data comes from two public sources: the BU COVID-19 State Policy Database and “Stay at Home Policies” from wikidata.
- What processes might have influenced what data was observed and recorded and what was not?
- The dataset only captures COVID-19 policies that were implemented from March of 2020 to December of 2022. This means that there are likely some policies that have escaped this dataset. In addition, the
start_stopvariable in the data indicates that the dataset contains both the start and end dates for COVID policies. This also that there may be policies in the dataset that are not repeated twice since they were either created before March of 2020 or ended after December of 2022. This means that the data collection dates certainly influenced what policies were recorded as well as the accuracy of certain policies in terms of whether or not they still exist in March of 2023.
- The dataset only captures COVID-19 policies that were implemented from March of 2020 to December of 2022. This means that there are likely some policies that have escaped this dataset. In addition, the
- What preprocessing was done and how did the data come to be in the form that you are using?
- The data was also curated manually by Virtual Student Federal Service Interns after being collected by the U.S Department of Health and Human Services. In addition, since much of the data came from the BU COVID-19 State Policy Database, the data would have been preprocessed by BU before being reprocessed by the HHS. The same can be said about the data in the dataset that came from wikidata, which likely means that the data would have been transformed to create consistency between the two data sources within this dataset.
- If people are involved, were they aware of the data collection and if so, what purpose did they expect the data to be used for?
- While people were not involved, the counties and states in the dataset implemented public policies that can be viewed, so the data collection would not have changed any of the data or data outcomes.
Data limitations
Identify any potential problems with your dataset.
Something that could cause a potential problem with our dataset is the comments variable. We wanted to leave this variable in the dataset, since we think it may provide valuable insight when we are analyzing and data and visualizations. The problem, however, is that this variable is not very easy to use in terms of visualizations and data analysis, since the comments vary quite drastically depending on the Covid-19 policy. This means that we may have to look at the raw dataset itself if we want to use this variable in our analyses or explanations. Another variable that may pose a problem is the start_stop variable in the original dataset, since it’s difficult determine which observation represents the beginning of a new policy and which ones represent the end. To address this, when tidying our data, we decided to break up this variable into “start” and “stop” and then created two separate datasets since not all the policies appear to have both a start and stop date, and we also want to keep these observations at hand since they may prove valuable later on.
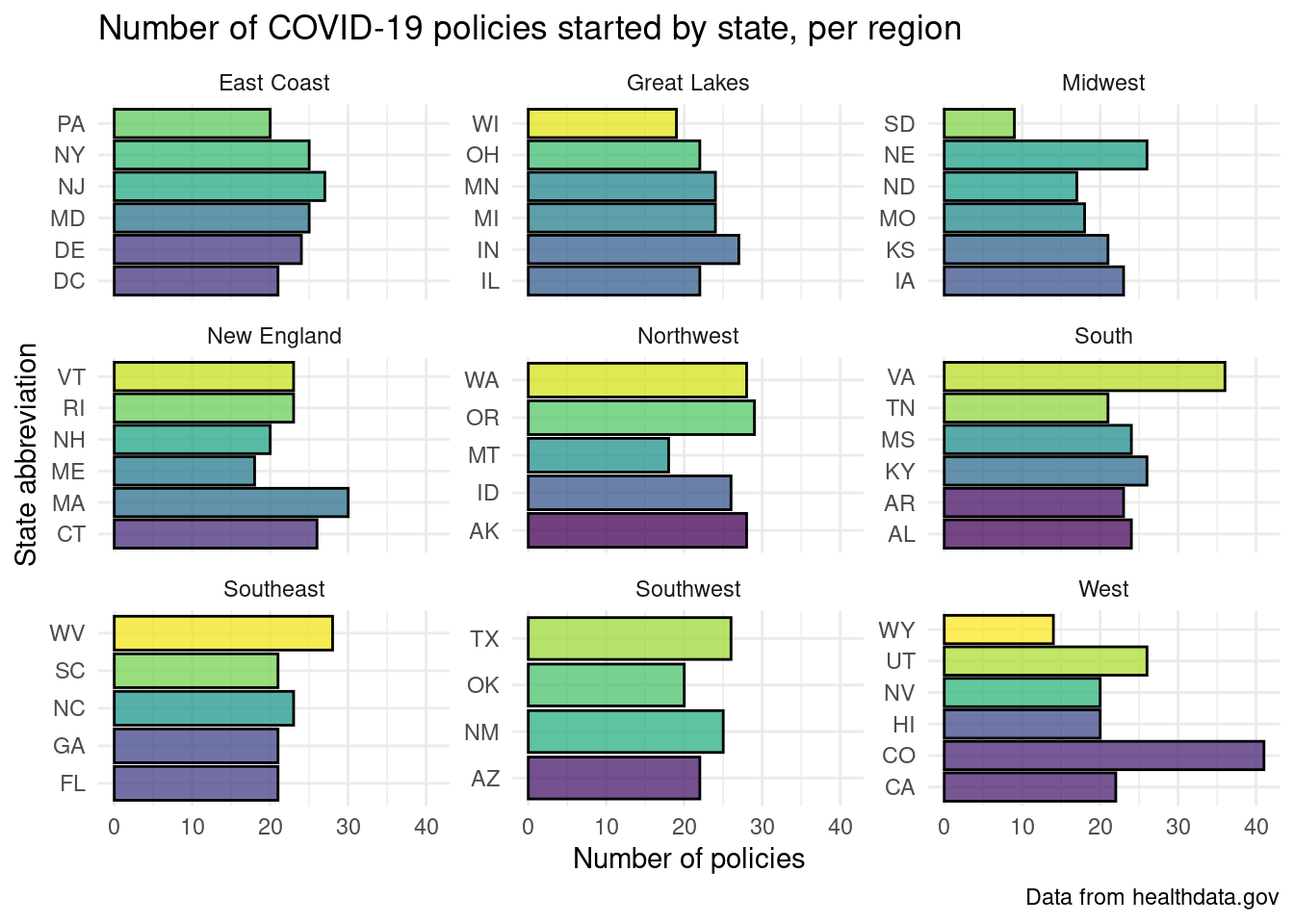
Exploratory data analysis
# A tibble: 56 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) 38.7 2.45 15.8 3.11e-51
2 stateAL 6.11 3.60 1.70 8.97e- 2
3 stateAR 7.32 3.64 2.01 4.46e- 2
4 stateAZ 5.91 3.69 1.60 1.09e- 1
5 stateCA 7.09 3.69 1.92 5.45e- 2
6 stateCO -3.63 3.17 -1.14 2.53e- 1
7 stateCT 1.86 3.52 0.528 5.98e- 1
8 stateDC 8.42 3.73 2.25 2.44e- 2
9 stateDE 6.20 3.60 1.72 8.54e- 2
10 stateFL 5.18 3.73 1.39 1.66e- 1
# ℹ 46 more rowsQuestions for reviewers
Are we allowed to conduct outside research to answer our research question?