Research question(s). State your research question (s) clearly.
How has the emergence of new industries and wealth types affected the geographic distribution and gender composition of billionaires over time?
What are the differences in total wealth between male and female billionaires across different industries and demographic age groups?
Data collection and cleaning
Have an initial draft of your data cleaning appendix. Document every step that takes your raw data file(s) and turns it into the analysis-ready data set that you would submit with your final project. Include text narrative describing your data collection (downloading, scraping, surveys, etc) and any additional data curation/cleaning (merging data frames, filtering, transformations of variables, etc). Include code for data curation/cleaning, but not collection.
Rows: 2755 Columns: 12
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (7): Name, Country, Source, Residence, Citizenship, Status, Education
dbl (4): NetWorth, Rank, Age, Children
lgl (1): Self_made
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
#organized billionaire dataset cleaned_billionaire <- billionaire |>#cleaned the names of the variables janitor::clean_names() |>#selected the variables that would be of focus for this explorationselect(name, net_worth, rank, age, children, status, education) |>#made a new column indicating level of education qualitativelymutate(education_level =case_when(grepl("Master", education) ~'Master',grepl("Doctorate", education) ~'Doctorate',grepl("Doctor", education) ~'Doctorate',grepl("Bachelor", education) ~"Bachelor",grepl("Graduate", education) ~"Bachelor",grepl("Drop Out", education) ~'Dropout',grepl("Ph.D", education) ~'Ph.D',grepl("EMBA", education) ~'Master',grepl("Diploma", education) ~'Highschool',grepl("University", education) ~'Bachelor',TRUE~'Other')) |>#made a new column indicating level of education quantitatively through years of educationmutate(years_education =case_when(grepl("Master", education_level) ~14,grepl("Doctorate", education_level) ~16,grepl("Bachelor", education_level) ~12,grepl("Dropout", education_level) ~8,grepl("Ph.D", education_level) ~18,grepl("Diploma", education_level) ~8,grepl("Other", education_level) ~NA,)) |>#made a new column indicating whether a billionaire attended an Ivy League or notmutate(ivy_league =if_else(is.na(education), FALSE,if_else(str_detect(education, "Harvard|Yale|Princeton|Columbia|Brown|Dartmouth|Cornell|University of Pennsylvania"),TRUE, FALSE)))
The first thing we did was we downloaded the data from the dataset from the https://corgis-edu.github.io/corgis/csv/ website as a csv file. From then onwards we imported the csv file into the data subfolder of the group project folder.
Once the data was uploaded, we reads the csv file from the data folder into a variable called “billionaire”. From then onwards we cleaned and filter the billionaire data frame. We first clean the columns names to be more consistent with conventions using janitor::clean_names(). After that, we selected only specific columns of interest that would be used in our data analysis and relevant to our exploration. We manually selected the 9 variables we want to examine further. Once we selected the relevant variables, we noticed that the remaining names of the data set included some names of families instead of individuals. As our research question is interested in how gender plays a role in determining the distribution and prevalence of billionaires, we decided that these data points would distract from our ability to answer the question. Therefore, we used filtered to include only rows where the demographics_gender column is either “male” or “female” using filter(). Finally, we also identified for some observations, the age value of some billionaires were 0 because the billionaire being observed was dead. We thought that the value 0 could be confusing as it didn’t make sense that someone’s age would be 0 hence we used mutate() to replace any 0 values in the demographics_age column with NA. The resulting data frame is then saved as cleaned_billionaire.
Data description
Have an initial draft of your data description section. Your data description should be about your analysis-ready data.
The billionaires.csv data set contains information about billionaires around the world. The observations (row) is a different billionaire and the attributes (columns) are different characteristics and information about the specific billionaire.
This data set was originally created to provide more insight into the billionaires in our society over the years and how various attributes have changed. The data builds off data originally collect by Forbes on the Forbes World’s Billionaires lists from 1996-2014. Scholars at the Peterson Institute for International Economics added additional variables for each billionaire that revealed important information.
A process that could have influenced what data was observed and recorded and what was not could be related to how Forbes originally compiled this list as this data set simply builds off the observations that Forbes have published publicly. Additionally, there could be information about other extremely wealthy individuals in the world that cannot be gathered resulting in their exemption in this data set.
The dataset has been cleaned and filtered. The resulting data set, cleaned_billionaire has 1,285 observations and 9 columns. The data set includes the following variables:
name: This variable contains the names of the billionaires and is a character string. For example, “Jeff Bezos” or “Alice Walton”.
rank: This variable contains the rank of each billionaire in terms of their net worth and is a double-precision floating point number. For example, 1 or 100.
year: This variable contains the year in which each billionaire’s net worth was estimated and is a double-precision floating point number. For example, 2022.
demographics_age: This variable contains the age of each billionaire and is a double-precision floating point number. For example, 50.
demographics_gender: This variable contains the gender of each billionaire and is a character string with two possible values: “male” or “female”.
location_country_code: This variable contains the country code of the country in which each billionaire is a citizen of and is a character string. For example, “US” or “CHN”.
location_gdp: This variable contains the GDP of the country in which each billionaire is a citizen of and is a double-precision floating point number. For example, 1.060000e+13.
wealth_type: This variable contains the source of each billionaire’s wealth and is a character string. For example, “self-made” or “inherited”.
wealth_worth_in_billions: This variable contains the net worth of each billionaire in billions of dollars and is a double-precision floating point number. For example, 48.0.
The dataset has been filtered to include only male and female billionaires, and missing age values (coded as 0) have been replaced with NA.
Data limitations
Identify any potential problems with your dataset.
A limitation of this could be that although the list has over 2800 rows of data, it does not include every billionaire that ever existed such as John D. Rockefeller, or people even older which can make the data slightly less accurate.
Certain people are listed on the dataset multiple times which can skew the data in their favor. This could be because certain billionaires might have fallen out of being a billionaire and then became one again, showing the result several times. People in the technology industry could have the biggest risk of this as there are many of competition and they could constantly fall in and out of being a billionaire, significantly skewing their results.
Some of the people on this list did not make become a billionaire by themselves but rather inherited the money. This can also cause inconsistency in the data since the parent and the heir would both be counted despite the money was only transferred over rather than made.
Another limitation of the data is that some billionaires could hold dual citizenship. And as the data set only includes one country as the country of citizenship for these billionaires, this information is also lacking. The lack of information for dual citizenship billionaires could give an incomplete representation of the distribution of billionaires in different geographical reasons.
Finally, one more limitation is that the observations in the data set are only billionaires known by the public and information known by the public. There could potentially be billionaires that exist without the knowledge of the public today, making it possible that any results derived from this data set to miss those values. Additionally, the information in the dataset is only what is known publicly, and some information could potentially be different from what the reality is since that information may not be disclosed.
Exploratory data analysis
Perform an (initial) exploratory data analysis.
*Use summary functions like mean and SD along with visual displays like scatterpoints and graphs to describe data.
Provide at least one model showing patterns or relationships between variables that address your research questions. This could be regression or clustering, or something else that measures some property of the dataset.*
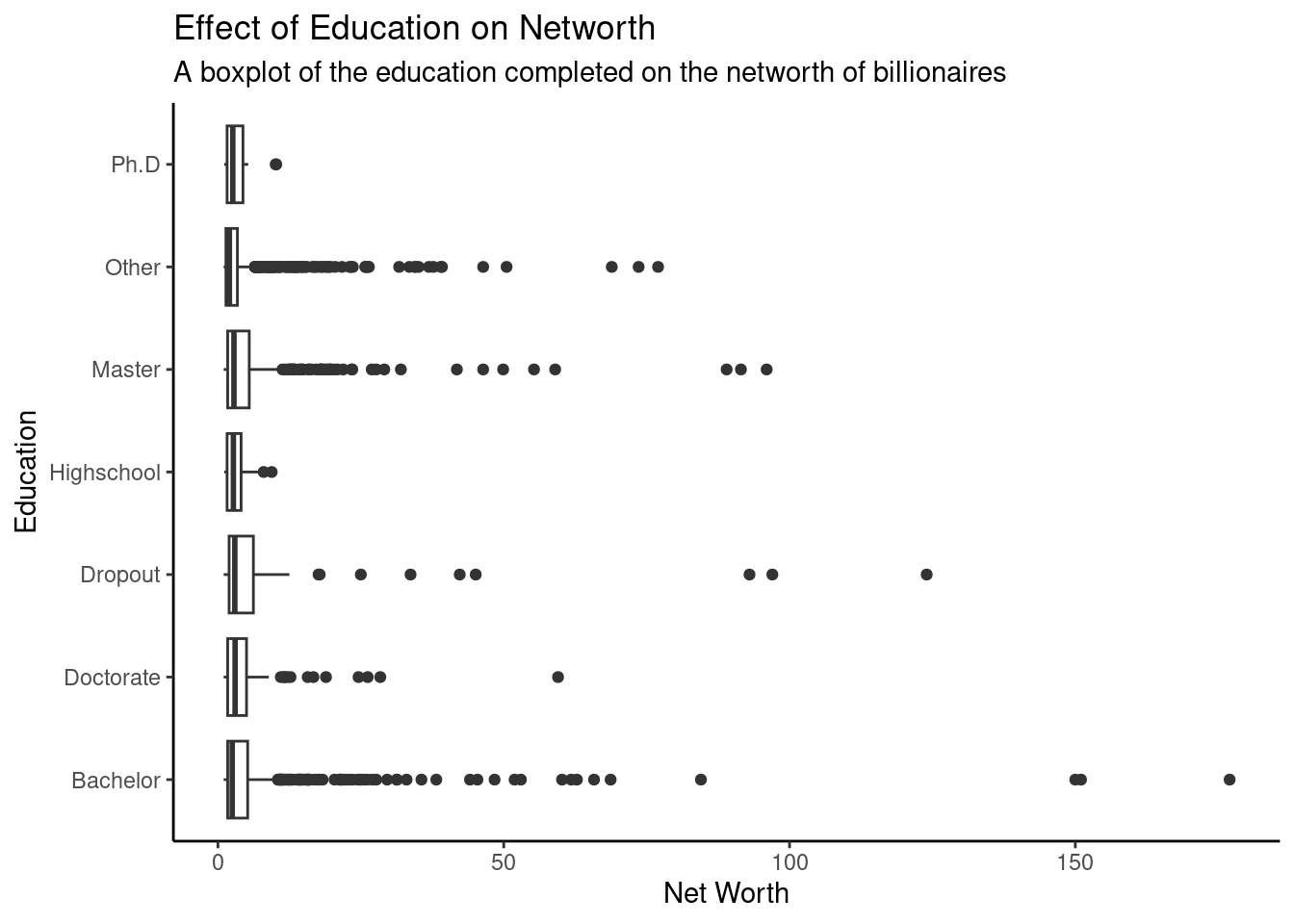
ggplot(cleaned_billionaire, aes(x = net_worth, y = education_level)) +geom_boxplot() +labs(x ="Net Worth",y ="Education",title ="Effect of Education on Networth",subtitle ="A boxplot of the education completed on the networth of billionaires" ) +theme_classic()
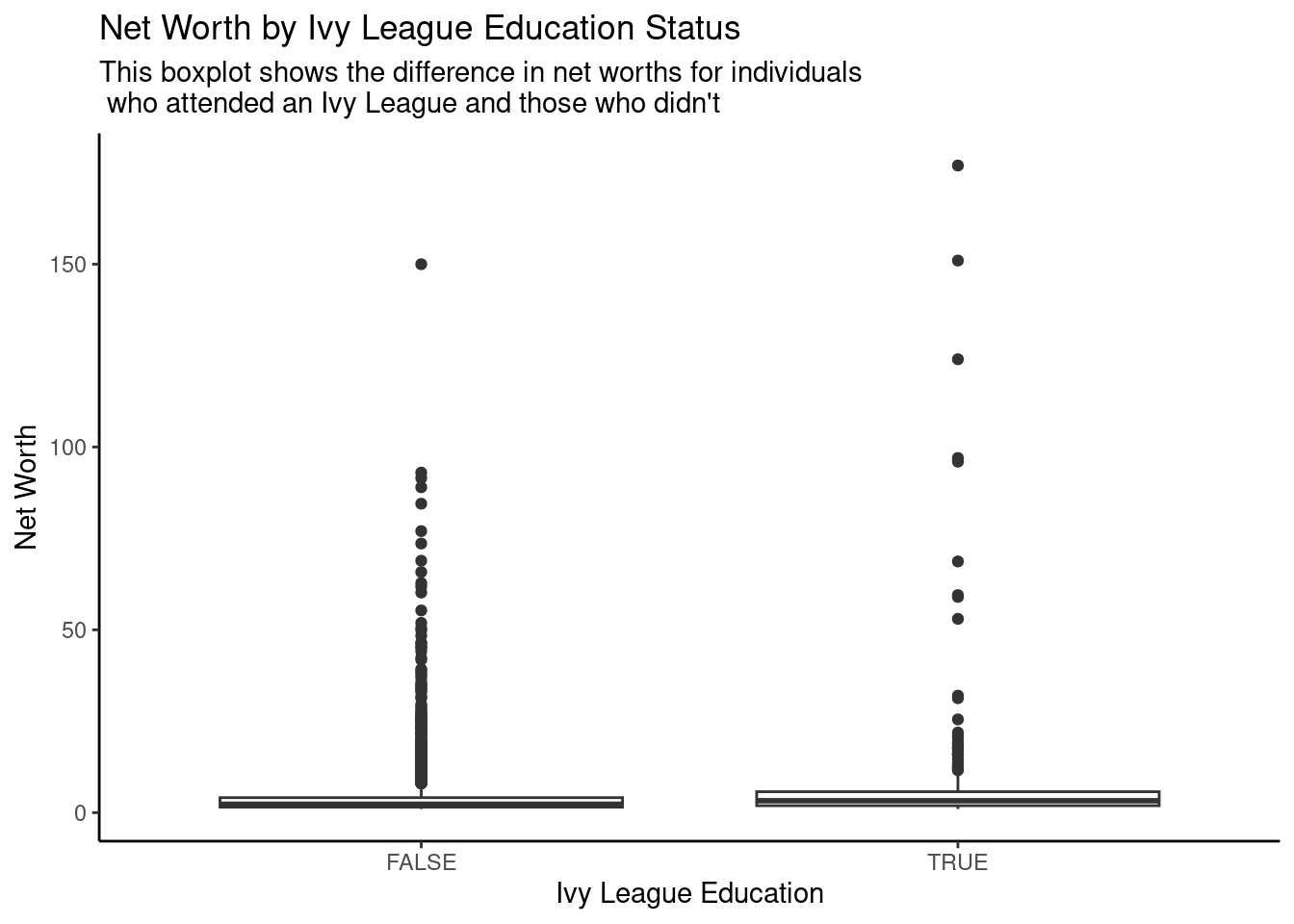
ggplot(cleaned_billionaire, aes(x = ivy_league, y = net_worth)) +geom_boxplot() +labs(x ="Ivy League Education",y ="Net Worth",title ="Net Worth by Ivy League Education Status",subtitle ="This boxplot shows the difference in net worths for individuals \n who attended an Ivy League and those who didn't") +theme_classic()
Questions for reviewers
1) What will this data set have the breadth to answer all analysis questions that our team will be required to complete during the project?
What is the best way of minimizing the skew in data where there are billionaires who appear in some years, whereas they don’t in others? How should we go about handling the changing list?
If we were to extrapolate the list’s information about the population and ratio of billionaires, what would you suggest we do if we wanted to predict the number of billionaires not on the Forbes 100 list but, in reality, are also billionaires?
What are the best practices to follow when tracking the position of billionaires on the list over time? If we wanted to show the movement of billionaires on the list over time?
Does our research question require enough of an ambitious exploration? What steps do you suggest we take to answer our research question first?
Should we look at individual variables before looking at more ones?
Our research question is trying to identify two things (the effect of new industries on gender and geographic distribution and the impact of new types of wealth on gender and geographic distribution). Is this okay?
What suggestions do you have for us to consider when working through this project?