We downloaded our data file analysis ready from the CORGIS website. Our data set did not need to be transformed, as all the variables were already in their suitable types.
We selected variables such as artist hotness, artist terms, song tempo, and song year to see how these variables interact with the song hotness variable.
We cleaned the variable names using the janitor library.
We filtered out all nonsensical values including values of 0 for song year and song hotness, and anything greater than 1 or below 0 for song hotness.
# A tibble: 2,712 × 5
artist_hotttnesss artist_terms song_hotttnesss song_tempo song_year
<dbl> <chr> <dbl> <dbl> <dbl>
1 0.402 pop punk 0.605 130. 2007
2 0.332 new wave 0.266 86.6 1984
3 0.448 country rock 0.405 120. 1987
4 0.513 hard rock 0.684 150. 2004
5 0.542 math-core 0.667 167. 2004
6 0.306 pop rock 0.495 138. 1985
7 0.416 soul jazz 0.414 110. 1972
8 0.418 doo-wop 0.443 130. 1964
9 0.393 gothic metal 0.451 115. 2007
10 0.468 ska punk 0.529 116. 2003
# ℹ 2,702 more rows
write.csv(music, "data/cleaned_music.csv")
Other appendicies (as necessary)
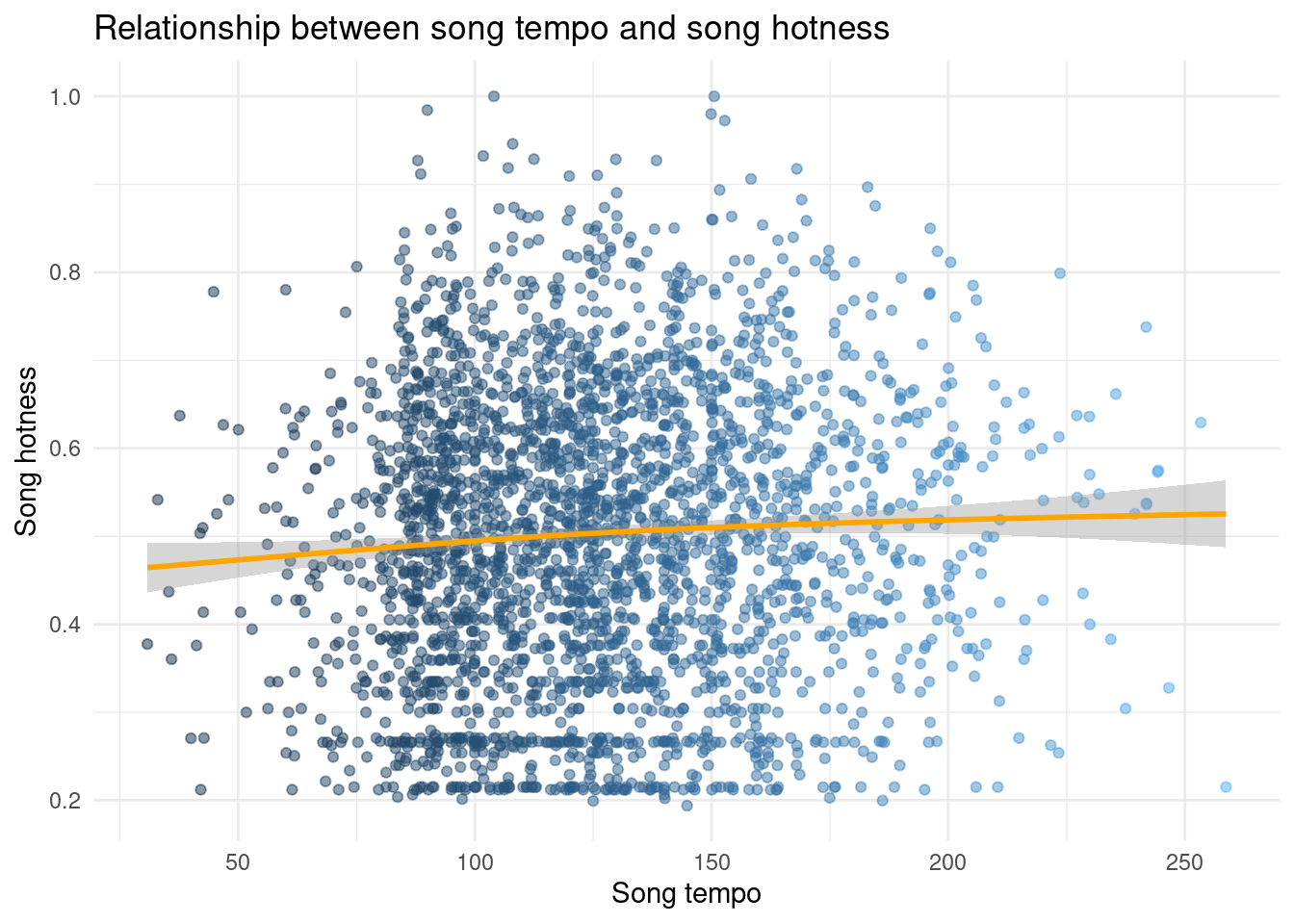
`geom_smooth()` using method = 'gam' and formula = 'y ~ s(x, bs = "cs")'
The scatterplot above shows the relationship between the song tempo and song hotness variables. We fit a geom_smooth line to investigate the strength of the relationship between the two variables. However, we chose to not further investigate this relationship due to the roughly horizontal line that indicated weak or potentially no correlation.