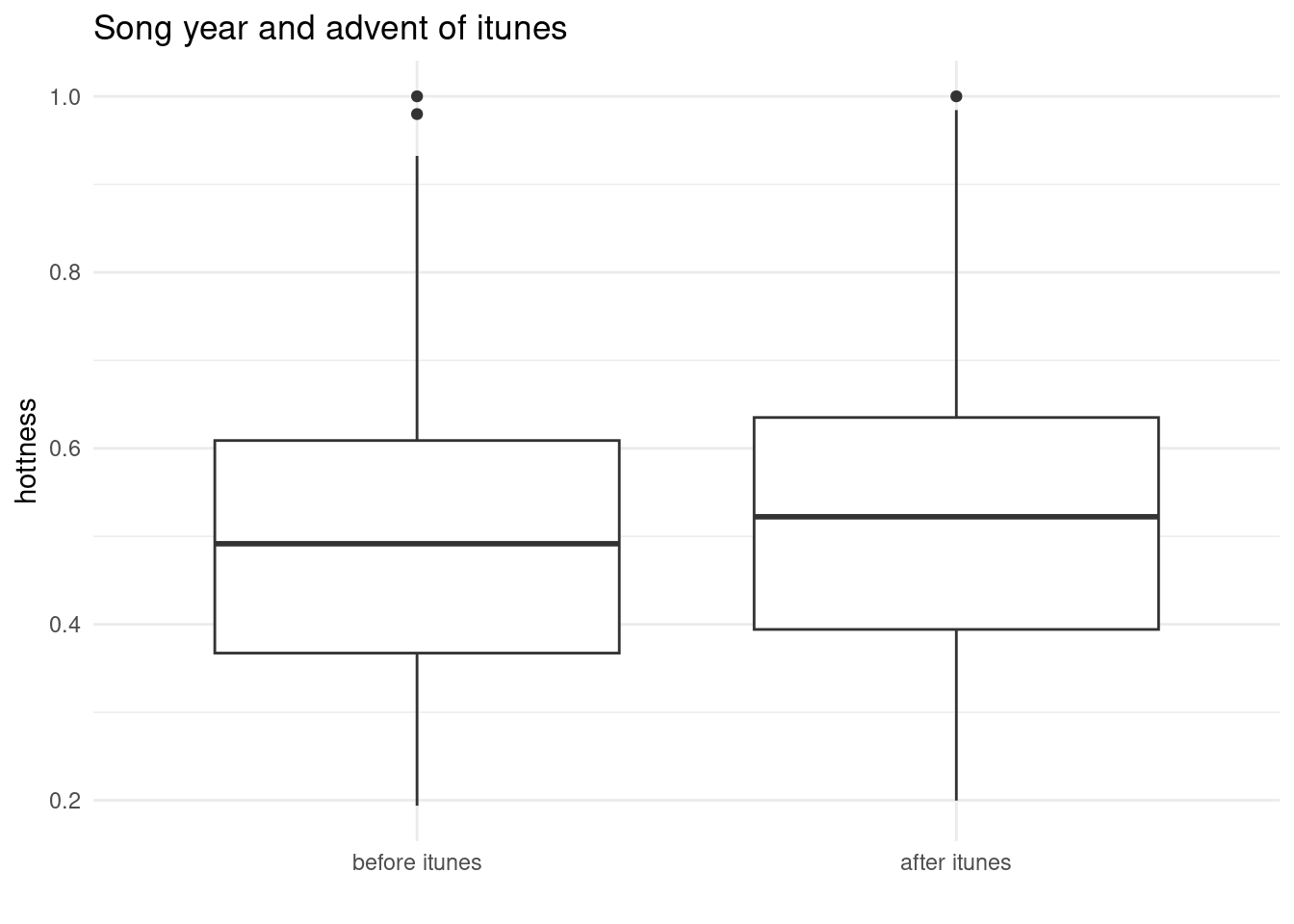Research question(s). State your research question (s) clearly.
What features makes up a popular song?
What is the relationship between artist popularity the year the song was released and the artists’ genre?
How does pop music compare to other genres in terms of different features?
Also, how do the pop genres compare to each other?
How has tempo or loudness influenced how popular songs are through the different decades?
Data collection and cleaning
Have an initial draft of your data cleaning appendix. Document every step that takes your raw data file(s) and turns it into the analysis-ready data set that you would submit with your final project. Include text narrative describing your data collection (downloading, scraping, surveys, etc) and any additional data curation/cleaning (merging data frames, filtering, transformations of variables, etc). Include code for data curation/cleaning, but not collection.
We downloaded our data file analysis ready from the CORGIS website. Our data set did not need to be transformed, as all the variables were already in their suitable types.
We plan on selecting variables such as artist hotness, artist terms, song key, song loudness, song tempo, and song year to see how these variables interact with the song hotness variable.
library(janitor)
Attaching package: 'janitor'
The following objects are masked from 'package:stats':
chisq.test, fisher.test
Rows: 10000 Columns: 35
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (4): artist.id, artist.name, artist.terms, song.id
dbl (31): artist.familiarity, artist.hotttnesss, artist.latitude, artist.loc...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
# clean names, filtered songs without years and hotness scores, selected relevant columnsmusic <- music |>clean_names() |>filter(song_year !=0) |>filter(song_hotttnesss !=0) |>filter(song_hotttnesss >=0& song_hotttnesss <=1) |>select(artist_hotttnesss, artist_terms, song_hotttnesss, song_loudness, song_tempo, song_year)music
# A tibble: 2,712 × 6
artist_hotttnesss artist_terms song_hotttnesss song_loudness song_tempo
<dbl> <chr> <dbl> <dbl> <dbl>
1 0.402 pop punk 0.605 -4.50 130.
2 0.332 new wave 0.266 -13.5 86.6
3 0.448 country rock 0.405 -8.58 120.
4 0.513 hard rock 0.684 -5.27 150.
5 0.542 math-core 0.667 -4.26 167.
6 0.306 pop rock 0.495 -12.3 138.
7 0.416 soul jazz 0.414 -11.9 110.
8 0.418 doo-wop 0.443 -10.9 130.
9 0.393 gothic metal 0.451 -7.47 115.
10 0.468 ska punk 0.529 -2.02 116.
# ℹ 2,702 more rows
# ℹ 1 more variable: song_year <dbl>
Data description
Have an initial draft of your data description section. Your data description should be about your analysis-ready data.
What are the observations (rows) and the attributes (columns)?
Each observation is a song. The attributes include features of the song, such as the song’s artist’s hotness, its artist terms, the song key, the song loudness, the song tempo, and the year the song was released.
Why was this dataset created? Who funded the creation of the dataset?
This dataset was created for a project collaboration between the Echo Nest and LabROSA, partly funded by the National Science Foundation of America, to research the field of Music Information Retrieval. The data is from a library called the Million Song Dataset.
What processes might have influenced what data was observed and recorded and what was not?
The data may have come from different song platforms, as the website did not say what platform their data sourced from, which may influenced how much data was observed and recorded, such as the songs with no associated release year.
What preprocessing was done, and how did the data come to be in the form that you are using?
The data was already cleaned up into a table format, with each attribute already it’s suitable type. We cleaned up and selected the attributes we are interested for our data to be in the from we are using.
If people are involved, were they aware of the data collection and if so, what purpose did they expect the data to be used for?
The labs involved were aware of the data collection, and they expected the database to be used to promote more research into the Music Information Retrieval field.
Data limitations
Identify any potential problems with your dataset.
Our dataset included observations that had no song release year associated with it (a value of 0 rather than a year). This could pose as a potential problem as it could provide useful data to make our analysis more informative.
Another potential problem in our dataset is for all the observations, the song name attribute is the integer 0, which is not informative or helpful for our analysis.
# A tibble: 299 × 2
artist_terms n
<chr> <int>
1 blues-rock 140
2 hip hop 127
3 post-grunge 74
4 dance pop 56
5 pop rock 49
6 hardcore punk 47
7 country rock 44
8 heavy metal 44
9 chanson 43
10 post-hardcore 43
# ℹ 289 more rows
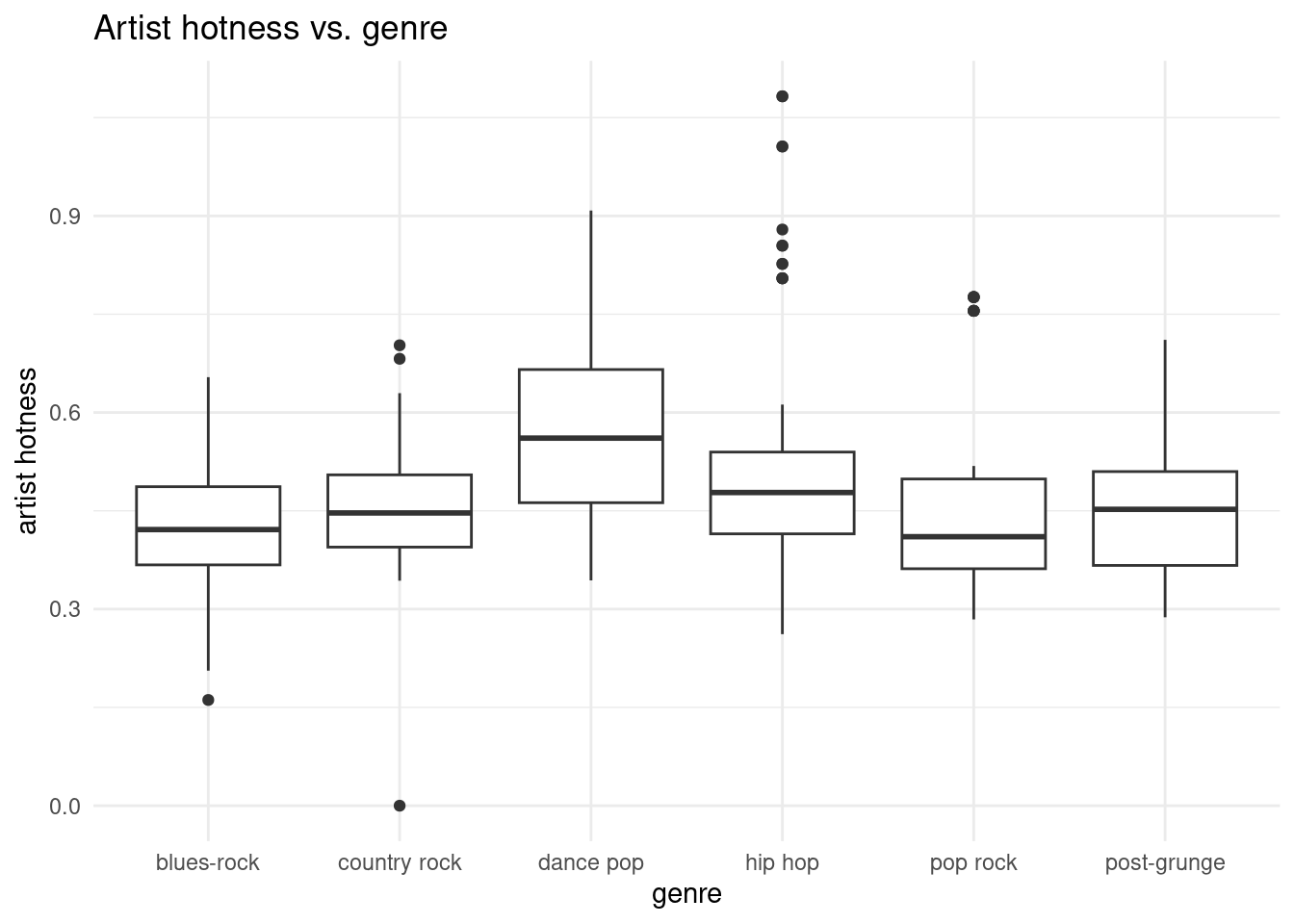
# boxplot of artist hotnessmusic |>filter(artist_terms %in%c("blues-rock", "hip hop", "post-grunge", "dance pop","pop rock", "country rock")) |>ggplot(aes(y = artist_hotttnesss, x = artist_terms) ) +geom_boxplot() +labs(title ="Artist hotness vs. genre",y ="artist hotness",x ="genre" ) +theme_minimal()
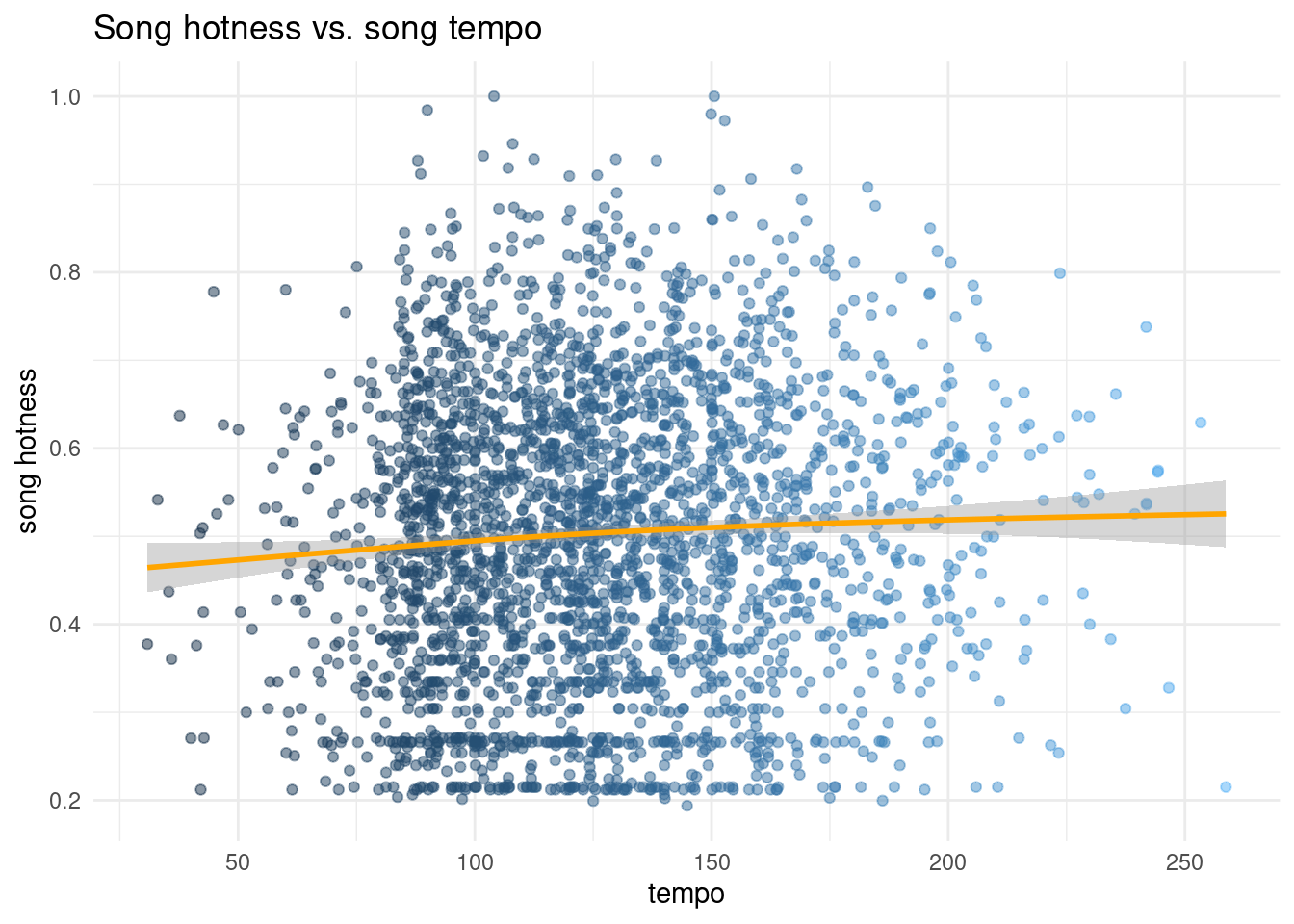
# scatterplot of song tempo vs. hotnessmusic |>filter(song_hotttnesss !=0, song_tempo !=0) |>ggplot(aes(x = song_tempo, y = song_hotttnesss, color = song_tempo)) +geom_point(alpha =0.5, show.legend =FALSE) +geom_smooth(color ="orange") +labs(title ="Song hotness vs. song tempo",x ="tempo",y ="song hotness" ) +theme_minimal()
`geom_smooth()` using method = 'gam' and formula = 'y ~ s(x, bs = "cs")'
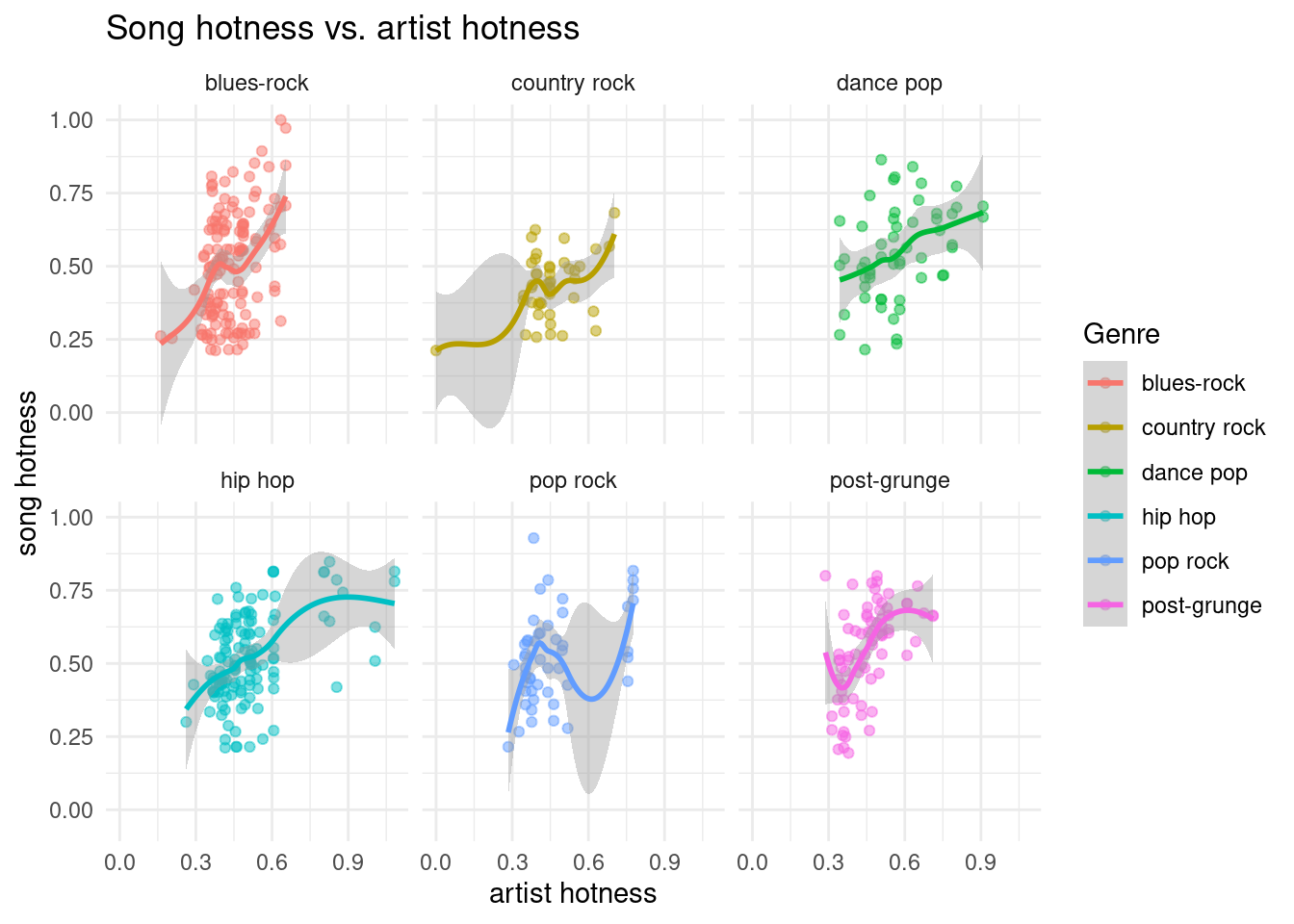
# scatterplots of artist vs song hotness, by genremusic |>filter(artist_terms %in%c("blues-rock", "hip hop", "post-grunge", "dance pop","pop rock", "country rock")) |>ggplot(aes(x = artist_hotttnesss, y = song_hotttnesss, color = artist_terms) ) +geom_point(alpha =0.5) +geom_smooth() +facet_wrap(facet =vars(artist_terms)) +labs(title ="Song hotness vs. artist hotness",x ="artist hotness",y ="song hotness",color ="Genre" ) +theme_minimal()
`geom_smooth()` using method = 'loess' and formula = 'y ~ x'
# boxplot of genre vs. song hotnessmusic |>filter(artist_terms %in%c("blues-rock", "hip hop", "post-grunge", "dance pop","pop rock", "country rock")) |>ggplot(aes(x = artist_terms, y = song_hotttnesss)) +geom_boxplot() +labs(title ="Song hotness vs. genres",x ="genre",y ="song hotness" ) +theme_minimal()
music |>filter(song_hotttnesss !=0) |>mutate(itunes_streaming =if_else(song_year >2003, "after itunes", "before itunes")) |>mutate(itunes_releveled =fct_relevel(.f = itunes_streaming, "before itunes", "after itunes")) |>group_by(itunes_streaming) |>ggplot(aes(x = itunes_releveled, y = song_hotttnesss) ) +geom_boxplot() +labs(title ="Song year and advent of itunes",x ="",y ="hottness" ) +theme_minimal()
Questions for reviewers
List specific questions for your peer reviewers and project mentor to answer in giving you feedback on this phase.
What variables seem most interesting in defining popularity to peers?
What genres seem best suited to compare and use?
In terms of interest and usability?
Should we combine all the subcategories of “pop” into one variable?
Which variables best tells a story of the data?
Which variables should we use to answer the question of: Do artists make their music with popularity in mind?
What interpretations or findings from the graph are most useful and/or interesting?
Are any of the graphs not useful or don’t contribute to our analysis?
Do you have suggestions for graphs that would be more informative or better at displaying the relationships?