# A tibble: 1 × 4
artist_mean tempo_mean song_mean obs
<dbl> <dbl> <dbl> <int>
1 0.455 126. 0.502 2712An Investigation of Song Popularity
Report
Introduction
As college students who frequently engage with music streaming platforms and are highly exposed to trends in pop culture, we were curious to explore these realms in the context of data. We looked into the Million Song Dataset that was collected for educational purposes, including variables such as the popularity levels of songs, artists, and various other attributes.
Our main research question was investigating the factors behind a song’s popularity. We then delved into figuring out if an artist’s previous popularity influenced a song’s popularity. Additionally, we investigated the impact of the creation of digital distribution of songs (i.e. iTunes) to see if that influenced songs’ overall popularity levels.
From our findings, after conducting statistical analysis, we concluded that an artist’s popularity, as well as the creation of digital distribution of songs, were, in fact, significant in impacting the popularity of songs.
Data description
This dataset was created for a project collaboration between the Echo Nest and LabROSA, partly funded by the National Science Foundation of America, to research the field of Music Information Retrieval. The data is from a library called the Million Song Dataset.
Each observation is a song. The attributes include features of the song, such as the song’s artist’s hotness, its artist terms, the song key, the song loudness, the song tempo, and the year the song was released. The data was already cleaned up into a table format, with each attribute already it’s suitable type. We cleaned up and selected the attributes we are interested for our data to be in the from we are using.
The data may have come from different song platforms, as the website did not say what platform their data sourced from, which may influenced how much data was observed and recorded, such as the songs with no associated release year. The labs involved were aware of the data collection, and they expected the database to be used to promote more research into the Music Information Retrieval field.
Data analysis
Before performing analysis, we cleaned up our data by cleaning the names, filtering out song years of 0, and selecting the columns that were most relevant to our analysis, including the following: artist_hotttnesss, artist_terms, song_hotttnesss, song_tempo, song_year.
Variables:
song_hotttnesss: numeric variable that has a range of 0 and 1 and represents the popularity of a song. This value was estimated for each song using an algorithm developed by Echo Nest.artist_hotttnesss: numeric variable that has a range of 0 and 1 and represents the popularity of an artist. This value was estimated for each song using an algorithm developed by Echo Nest.artist_terms: character variable that represents the different song genres.song_tempo: numeric variable that represents the tempo of the song is beats per minute.song_year: numeric variable that represents the release year of the song.
Using our selected columns, this tibble above summarizes the mean of each.
# A tibble: 299 × 2
artist_terms n
<chr> <int>
1 blues-rock 140
2 hip hop 127
3 post-grunge 74
4 dance pop 56
5 pop rock 49
6 hardcore punk 47
7 country rock 44
8 heavy metal 44
9 chanson 43
10 post-hardcore 43
# ℹ 289 more rowsThis tibble above represents the artist_terms (genre) in descending order of number of observations. We used this information in choosing genres for our analysis because we wanted to have the most amount of observations to work with.

We created these boxplots above to visualize the spread of the variable artist hotness for the 6 most popular artist_terms (genres). It appears as though the songs that are from the dance pop genre have the highest median artist hotness as well as greatest IQR. The songs from hardcore punk have the second highest median artist hotness, but they have the lowest IQR. The other 4 genres vary in their median artist hotness, but their IQRs appear to be roughly similar. As for other interesting observations, we noticed that the hip hop genre has a few high outliers and the hardcore punk genre has a few low outliers.

We created these boxplots above to visualize the spread of the variable song hotness for the 6 most popular artist_terms (genres). It appears as though the hardcore punk genre has the highest median song hotness, and the lowest IQR, while the others have similar median song hotnesses, and similar IQRs. The only exception is blues-rock, which has the highest IQR and overall spread. Finally, pop rock has a high outlier and hardcore punk has a few low outliers.
We also looked at the relationship between song tempo and song popularity, referenced in our appendices.
# A tibble: 2 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) 0.198 0.0116 17.1 2.54e- 62
2 artist_hotttnesss 0.667 0.0248 27.0 5.04e-142
The correlation coefficient is 0.4598708There is a weak positive correlation between artist hotness and song hotness as represented by the correlation value of 0.460. We decided to split the data up by genre to see if we could find more interesting results that could be investigated further.
The intercept of 0.198 means that when the artist hotness is zero, we can expect the song hotness to be 0.198, on average. The slope of 0.667 means that for every 1 unit increase in artist hotness, we can expect the song hotness to be higher by 0.667, on average.
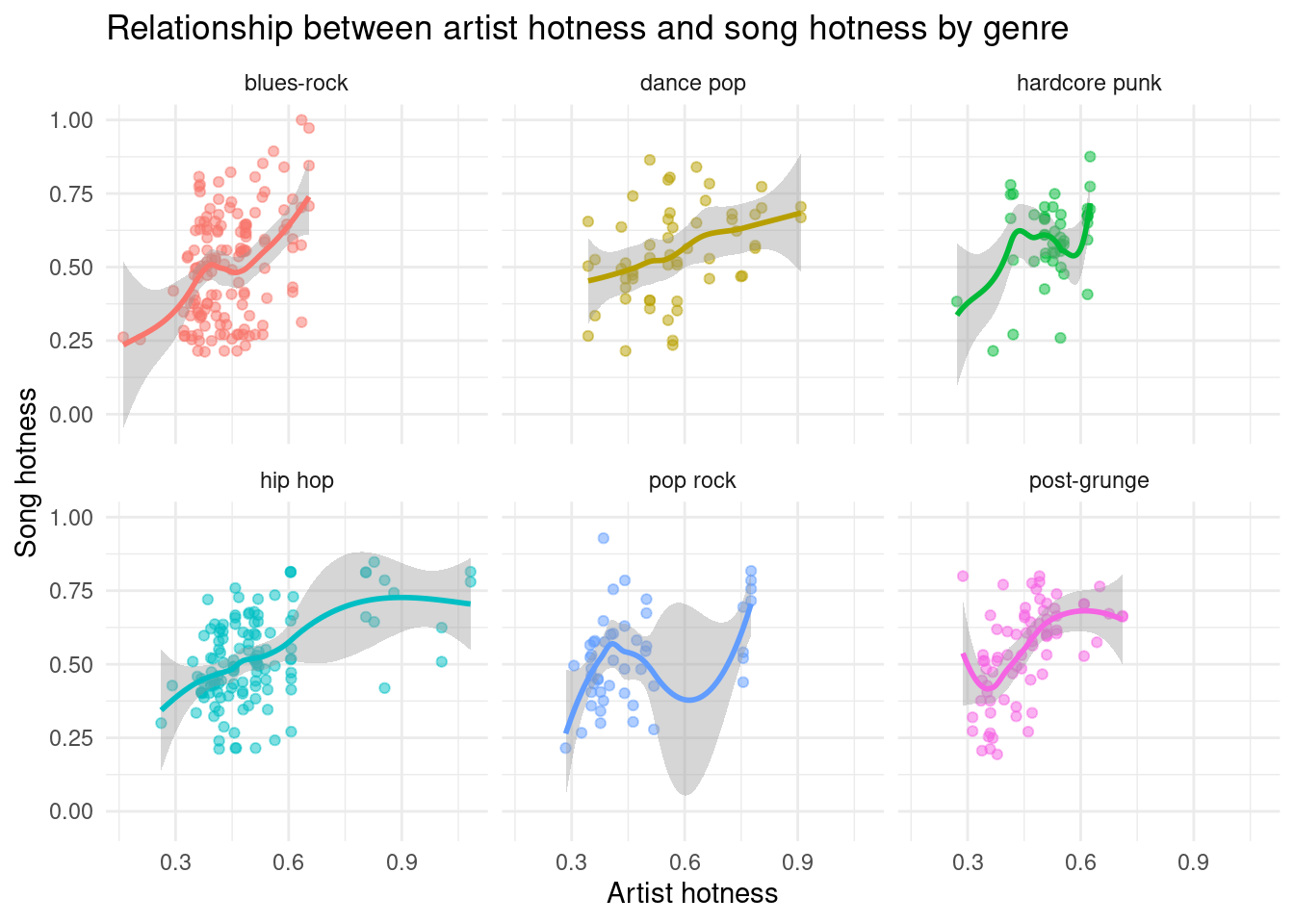
In the scatterplots above, we are investigating the relationship between artist hotness and song hotness for the top 6 artist terms (genres). Based on the roughly positive geom_smooth lines drawn, we believed there could be a correlation and wanted to further investigate this relationship for all the songs in our cleaned dataset, not just the top 6 genres.

We were curious about the popularity of songs before and after the creation of streaming platforms, so we looked into the spread of the song hotness variable before and after 2003, which was when iTunes was created. There is a slight difference in their medians, while they have similar IQRs, so we chose to further investigate this.
Evaluation of significance
Hypothesis Test 1:
Question: Do popular songs tend to come from more popular artists?
Our hypothesis: We hypothesize that more popular songs (song_hotttnesss >= 0.7) will come from artists that are more popular (artist_hotttnesss >= 0.7) as well. We believed that 0.7 was a good threshold for popularity. We performed a two-sided hypothesis test in order to be more objective.
Null: The true proportion of songs that are popular and were created by a popular artist is no different from the true proportion of songs that are not popular and/or not created by a popular artist.
\[ H_0: p_{popular} - p_{unpopular} = 0 \]
Alternative: The true proportion of songs that are popular and were created by a popular artist is different from the true proportion of songs that are not popular and/or not created by a popular artist.
\[ H_A: p_{popular} - p_{unpopular} \neq 0 \]

# A tibble: 1 × 1
p_value
<dbl>
1 0Hypothesis Test 2:
Question: Did the creation of streaming platforms increase the popularity of songs?
Our hypothesis: We hypothesize that creation of streaming platforms does increase the popularity of songs. We performed a two-sided hypothesis test in order to be more objective.
Null: The true median popularity of songs after the creation of iTunes in 2003 is no different from the true median popularity of songs before the creation of iTunes.
\[ H_0: median_{before} - median_{after} = 0 \]
Alternative: The true median popularity of songs after the creation of iTunes in 2003 is different from the true median popularity of songs before the creation of iTunes.
\[ H_A: median_{before} - median_{after} \neq 0 \]

# A tibble: 1 × 1
p_value
<dbl>
1 0Interpretation and conclusions
Hypothesis 1 Interpretation:
Since the p-value is smaller than 0.05, we reject the null hypothesis in favor of the alternative hypothesis. The data provides convincing evidence that the true proportion of songs that are popular and were created by a popular artist is different than the true proportion of songs that are not popular and/or not created by a popular artist.
In a real-life context, people tend to be bandwagoners. People tend to follow trends including already established artists and are also creatures of habit. Like network effects, more popular artists tend to attract more listeners and followers. Therefore it is harder and takes longer for new emerging artists to break into the entertainment industry.
Hypothesis 2 Interpretation:
Since the p-value is smaller than 0.05, we reject the null hypothesis in favor of the alternative hypothesis. The data provides convincing evidence that the true median popularity of songs after the creation of iTunes in 2003 is different than the true median popularity of songs before the creation of iTunes.
In a real-life context, the digital distribution of music has increased its accessibility and therefore its popularity. Additionally, knowing that iTunes also allowed users to download and buy individual songs separately from their albums, this could have also had an effect of the p-value and our interpretation of it.
Limitations
The original dataset included observations that had no song release year associated with it (a value of 0 rather than a year). This could pose as a potential problem as it could provide useful data to make our analysis more informative. Another potential problem in our dataset is for all the observations, the song name attribute is the integer 0, which is not informative or helpful for our analysis.
In terms of the second hypothesis, the data we used had observations until 2011. iTunes began in 2003 and other streaming platforms followed in the early 2000s. Therefore, there may not be enough data to accurately conclude to the fullest extent that song popularity increased as streaming platforms became available.
The variables song hotness and artist hotness were a bit murky as we did not know exactly what went into calculating these values. We only saw that an algorithm was involved in coming up with a number between 0 and 1. Our threshold of 0.7 for the song hotness vs artist hotness hypothesis test was arbitrary - we thought it struck a good balance at a value which was high, but not too high.
The music dataset contained a lot of different specific genres and sometimes genres were split into subcategories such as pop-rock and pop-country for example. This made it difficult to focus on specific genres in our analyses and we chose to look at our filtered dataset as a whole. In the future, we would like to investigate how popular songs are influenced by different factors by genre as well.
Acknowledgments
We would like to acknowledge our amazing professor Benjamin Soltoff for teaching us the fundamentals of data science to create this project, and our project mentor Marina Zafiris for providing us valuable feedback to guide our project in the right direction. We also would like to acknowledge the course INFO 2921: Inventing An Information Society for informing us on the impact of the creation of iTunes and the overall digital distribution of music. We would also like to acknowledge the Million Song Dataset for providing a multifaced dataset for us to conduct a research question on.
Finally, we would like to acknowledge all of the team members on this team for always working together and having fun struggling through merge conflicts.